[AINews] Tencent's Hunyuan-Large claims to beat DeepSeek-V2 and Llama3-405B with LESS Data • ButtondownTwitterTwitter
Chapters
AI Twitter and Reddit Recap
Tencent's 389B MoE Model and Tensor Parallelism Enhancements
Innovations in AI and Technology
Discord Community Highlights
Exploring HuggingFace Community Conversations
Using Claude Haiku as Editor Model
Collaboration and Development Updates
Interconnects ML Drama
Interconnects - Random Messages
Distributed Training of LLMs and Kubernetes Implementation
Mozilla DevRoom at FOSDEM 2025
AI Twitter and Reddit Recap
AI Twitter Recap
- Claude 3.5 Haiku announced by AnthropicAI to be fastest and most intelligent cost-efficient model
- Meta opens Llama AI for U.S. defense sector
- Tool to transform meeting recordings into actionable insights introduced by TheRundownAI
- LlamaIndex chat-ui React component library unveiled
- MLX LM advances with faster text generation and KV cache quantization
- Self-evolving online curriculum RL framework proposed by omarsar0
- Systematic survey on evaluating Large Language Models released by sbmaruf
AI Reddit Recap
/r/LocalLlama Recap
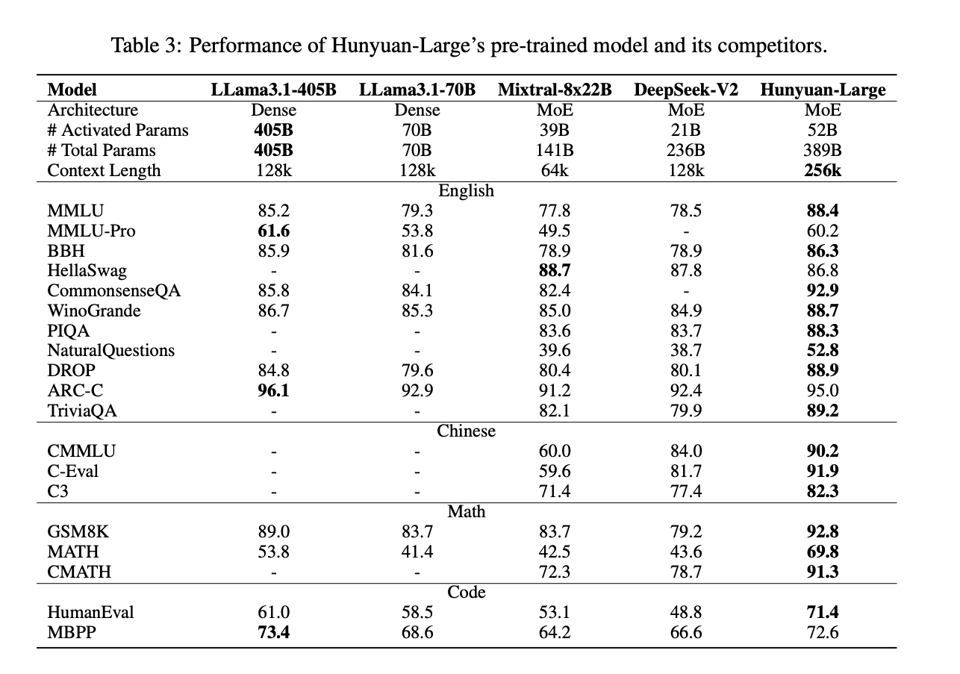
- Tencent's Hunyuan-Large model discussed as a game changer in open-source models
- Tencent's release of a 389B MoE model known for data efficiency and novel approaches showcased
Tencent's 389B MoE Model and Tensor Parallelism Enhancements
Tencent introduced the Hunyuan-Large model with 389B parameters to rival Llama, utilizing MoE for efficient scaling. Discussions highlighted its massive size requiring 200-800 GB memory. Users expressed concerns about hardware limitations, including GPU sanctions in China. Meanwhile, enhancements in Llama models like Tesla P40 GPUs doubling context sizes and optimizing GPU performance were noted. RTX 3090 benchmarks showcased varying performance with tensor parallel implementations. Discussions also explored Qwen2.5-Coder analysis and the anticipation for the release of Qwen2.5-Coder-32B. Other themes included voice cloning technology, speculative decoding techniques, and competitive advances in coding models. The section covers topics related to AI model advancements, benchmark insights, and future developments in the AI field.
Innovations in AI and Technology
The section discusses various advancements in AI and technology across different Discord channels. It covers topics such as the launch of new AI models like Hume App combining EVI 2 and Claude 3.5 Haiku, OpenAI's reductions in GPT-4 latency with Predicted Outputs, the introduction of tools like Supermemory for managing digital content, and developments of large-scale models like Tencent's Hunyuan-Large. Additionally, there are discussions on model performance evaluations, optimization techniques, and the challenges faced in implementing and utilizing AI technologies effectively. The section also highlights community interactions, sharing of resources, and the ongoing efforts to enhance AI capabilities for various applications.
Discord Community Highlights
The OpenInterpreter Discord featured discussions on Microsoft's Omniparser integration, real-time previews, and tool enhancements. The Modular (Mojo) Discord had conversations about community Q&A, effect systems, and matrix multiplication errors. DSPy Discord introduced a new Election Candidate Research Tool and discussed optimizations. OpenAccess AI Collective (axolotl) Discord engaged in distributed training, fine-tuning models, and introduced the Firefly model. Torchtune Discord talked about DistiLLM optimization, VinePPO challenges, and Hailo reverse engineering. Tinygrad (George Hotz) Discord shared TokenFormer integration, dependency resolution queries, and Hailo reverse engineering efforts. LLM Agents (Berkeley MOOC) Discord announced Lecture 9 on Project GR00T and introduced Dr. Jim Fan. Mozilla AI Discord discussed FOSDEM 2025 opportunities, call for volunteer, and proposal preparation resources. Gorilla LLM (Berkeley Function Calling) Discord focused on benchmarking function calls and discussed the need for indexed function definitions.
Exploring HuggingFace Community Conversations
The HuggingFace community is abuzz with discussions on various topics. Members are sharing insights and queries related to tools like FastBert Tokenizer and AutoTokenizer. The community showcases enthusiasm for innovative developments like Aud2Stm2Mdi, a tool to enhance audio processing capabilities with AI. Additionally, discussions in other channels focus on challenges and advancements in fields like computer vision, NLP, diffusion models, and more. The conversations highlight the collaborative and engaging nature of the HuggingFace community.
Using Claude Haiku as Editor Model
Several discussions arose around using Claude 3 Haiku as an editor model, especially when the main model lacks strong editing capabilities. Members indicated that using a robust model like Haiku for editing can simplify the development process, particularly in languages requiring precise syntax management.
Collaboration and Development Updates
Highlighted the GitHub link for the W2S project, encouraging community contributions. This could lead to enhanced collaboration on project development. A link to the GitHub repository was provided for contributing to EleutherAI/w2s development. Additionally, discussions in the Eleuther LM Thunderdome channel included topics like controlling attempts in evaluation, opening a PR for LLM Robustness Evaluation, addressing inference hanging issues, handling NCCL out of memory errors during lm_eval, and making batch size adjustments to avoid memory issues. The LM Thunderdome channel also shared links to relevant PRs and documentation. In a separate section, the web page featured discussions from other AI-related channels like Unsloth AI, LM Studio, Hardware Discussion, and Latent Space, covering topics such as Python 3.11 performance improvements, qwen 2.5 model support, fine-tuning with small datasets, training methodologies, issues with unsloth library updates, community dynamics in AI-related discussions, Windows scheduler inefficiencies, GPU vs CPU optimization, context handling in LLMs, laptop cooling techniques, and memory bandwidth limitations.
Interconnects ML Drama
A member expressed a desire to share internal GPU drama but couldn't disclose details. Another member offered ssh access to their V100s in response to the GPU drama discussion, showing a willingness to collaborate and share resources.
Interconnects - Random Messages
Interconnects (Nathan Lambert) ▷ #random (19 messages🔥):
- Subscriber verification: Discussed the challenges of setting up subscriber verification after a Substack gift giveaway.
- Members Ready to Work on Tulu 3: Enthusiasm expressed to engage with Tulu 3 project.
- Transformer Insights from Felix Hill: Skip connections in a 96-layer transformer impact semantics directly.
- Encouraging Classmates in AI Engagement: Efforts to engage capable but less engaged classmates.
- Exploring Discord Verification Apps: Discussion on Discord apps for user verification and challenges faced.
- Tweet Link: Felix Hill Tweet
Distributed Training of LLMs and Kubernetes Implementation
A user explores distributed training on GPUs and CUDA libraries to improve training performance for LLMs. They delve into the complexities of multi-GPU training and issues related to the integration of Kubernetes for fault tolerance in their GPU system. They aim to streamline the process and enhance the management of distributed training tasks by leveraging these tools and frameworks. Additionally, they discuss pretraining resources, specifically focusing on datasets and tokenization configuration to enable efficient training with small datasets.
Mozilla DevRoom at FOSDEM 2025
- Mozilla is hosting a DevRoom at FOSDEM 2025 in Brussels on February 1-2, 2025.
- Participants can submit talk proposals until December 1, 2024, with acceptance notifications by December 15.
- Diverse topics like Mozilla AI, Firefox innovations, and Privacy & Security are encouraged, with talks ranging from 15 to 45 minutes.
- Volunteers are needed for FOSDEM, with travel sponsorships available for European participants.
- Helpful resources for talk proposals are shared by Mozilla to assist speakers.
- Questions about the event can be addressed through the Mozilla Discord for clarifications.
FAQ
Q: What is the Claude 3.5 Haiku model announced by AnthropicAI?
A: Claude 3.5 Haiku is a model introduced by AnthropicAI that is claimed to be the fastest and most intelligent cost-efficient model.
Q: What AI development did Meta make for the U.S. defense sector?
A: Meta opened Llama AI for the U.S. defense sector.
Q: What tool was introduced by TheRundownAI to transform meeting recordings?
A: TheRundownAI introduced a tool to transform meeting recordings into actionable insights.
Q: What advancement was made in MLX LM?
A: MLX LM advanced with faster text generation and KV cache quantization.
Q: What self-evolving online curriculum RL framework was proposed by omarsar0?
A: omarsar0 proposed a self-evolving online curriculum RL framework.
Q: What was released by sbmaruf in the AI field?
A: sbmaruf released a systematic survey on evaluating Large Language Models.
Q: What model did Tencent introduce that was discussed as a game changer in open-source models?
A: Tencent introduced the Hunyuan-Large model with 389B parameters, discussed as a game changer in open-source models.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!