[AINews] s{imple|table|calable} Consistency Models • ButtondownTwitterTwitter
Chapters
AI Recap on Twitter and Reddit
Comparing Qwen 2.5 and Llama 3.2 in AI Models
Recent Discord Discussions
Torchtune Discord
Model Exploration and Enhancements
Noise Assignment in Diffusion Models
Perplexity AI Features and Announcements
Understanding GPU Mode Discussions
Collaborative AI Projects Discussion
Interconnects - Nathan Lambert News
Exploring Attention in Tinygrad and Other Optimizations
Social Networks and Footer
AI Recap on Twitter and Reddit
AI Twitter Recap:
- AI Hardware performance is advancing rapidly with significant achievements reported by various companies.
- AI models and releases like Stable Diffusion 3.5 and new multilingual models by Cohere are generating excitement in the AI community.
- AI tools and applications updates from LangChain and Perplexity AI, offering enhanced features and productivity boost.
- AI company news and partnerships announcement such as Meta's release of quantized Llama 3.2 models and Snowflake's collaboration with ServiceNow for AI-driven innovation.
AI Reddit Recap:
/r/LocalLlama Recap:
- Discussions around Gemma 2 27B emerging as a top performer for single-GPU inference, along with recommendations and performance comparisons with other models like Qwen 2.5.
- Evaluation of the best 3B model available currently with insights on GPU-Poor Leaderboard recommendations for small language models.
- Debates on model performances and comparisons to identify optimal choices based on quantization, context window, and hardware specifications.
Comparing Qwen 2.5 and Llama 3.2 in AI Models
Users in the AI community compared the performance of Qwen 2.5 and Llama 3.2 models, showcasing conflicting experiences. Some users reported hallucinations with Qwen 2.5 but praised its overall knowledge base. On the other hand, Llama 3.2 was noted for its better adherence to prompts. The discussion highlighted the nuances in the performance of these AI models and the varied experiences users had with each.
Recent Discord Discussions
This section provides insights into various discussions across different Discord channels focusing on topics such as censorship implications, AI robotics integration, model performance issues, AI language capabilities, and more. Members engage in debates, share feedback, and seek advice on optimizing AI applications, implementing new features, overcoming challenges with model performance, and exploring the potential of AI technologies in different domains.
Torchtune Discord
Tensor Parallelism Achieves Speedy Fine-Tuning:
Upon implementing Tensor Parallelism for multi-GPU fine-tuning, epochs clocked in under 20 minutes, showcasing impressive training velocity.
- Users expressed satisfaction with their configurations, highlighting that this setup meets their rapid training goals.
Batch Size Clarity in Multi-GPU Setup:
Members confirmed using batch_size = 6 across 8 GPUs results in a global batch size of 48, clearing up previous confusion regarding the scaling.
- This insight helped streamline the distributed training process, optimizing workflow for many users.
Dataloader Performance Bottlenecks Revealed:
Participants raised concerns about dataloader slowdown due to settings like num_processes=0 and insufficient pinned memory.
- Suggestions emerged for optimizing these settings to enhance training efficiency and mitigate performance drops.
Packed vs Unpacked Training Performance Differences:
Discussion highlighted mixed results between packed=True and packed=False training configurations, with the former sometimes speeding up processes.
- However, packed data produced unexpected responses, prompting further analysis into optimal usage.
Inquiry on muP Parameterizations Progress:
A user inquired about the status of muP parameterizations for recipes, referencing earlier discussions and seeking clarity on their implementation.
- This indicates ongoing community interest in feature development and the necessity for concrete updates moving forward.
Model Exploration and Enhancements
The section discusses different models and developments in the AI field. It starts with the introduction of Aya Expanse by Cohere to bridge the language gap in AI, followed by Meta's quantization enhancements for Llama models at Connect 2024. The community's efforts in data quantization aim to improve accessibility for developers. Additionally, it covers the launch of datasets like Naijaweb and Stable Diffusion Prompts to enhance model training and performance. A new Discord bot, Companion, focused on community safety, is also mentioned. Furthermore, it explores object detection and facial recognition models like YOLOv8 and FaceNet for comprehensive AI capabilities. The section ends with a discussion on automation in CAD design, challenges in dataset formatting for Llama models, and the importance of token understanding in model selection.
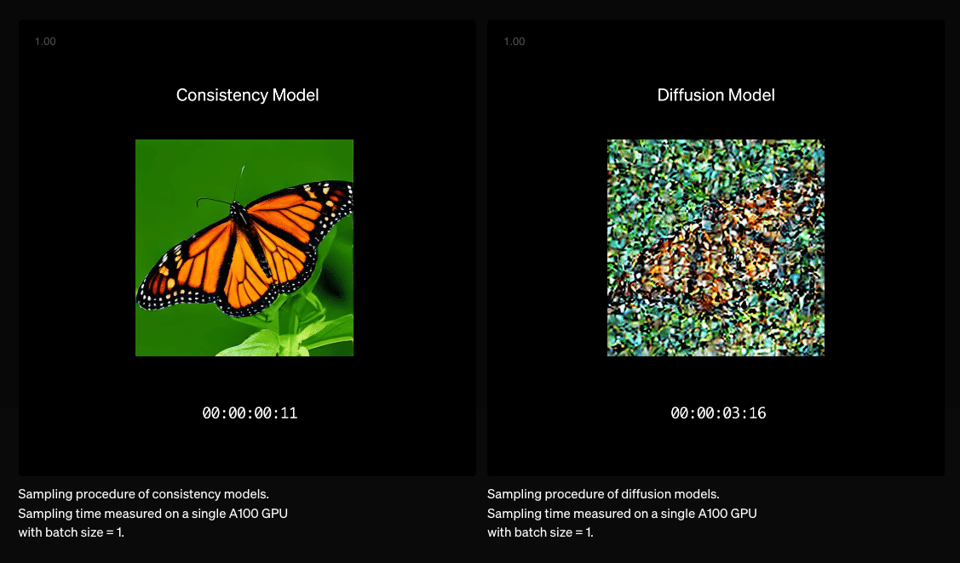
Noise Assignment in Diffusion Models
The section discusses the exploration of noise assignment in diffusion models to enhance generation. Concerns about the complexity of the linear assignment problem and the importance of maximizing mutual information in VAEs were highlighted. A new method called Representation-Conditioned Generation (RCG) was introduced to bridge unconditional and conditional generation. The discussions also touched upon implicit learning in consistency models, computational challenges in high-dimensional noise assignment, and the balance between computational efficiency and effective noise assignment for improved generation performance.
Perplexity AI Features and Announcements
Perplexity AI has officially arrived on MacOS, offering features such as Pro Search, voice and text question capabilities, Thread Follow-Up, and cited sources for every answer. Users can opt for a subscription model for Perplexity Pro through their iTunes account, ensuring access to premium features with effective subscription management. The community discusses performance issues on the MacOS App, queried Pro account logins, and reflections on model usage in Perplexity. There are also discussions on MacOS app performance, model performance comparisons, SB1047 legislation impacts, AI localization in anime, and Minecraft benchmarking. Members also share about NVIDIA's ROS integration, the alleged Bitcoin creator, Distil Whisper Large model, Jio-Disney merger challenges, and Garmin technology insights.
Understanding GPU Mode Discussions
The content discusses various topics related to GPU mode, including CUDA stream synchronization, numerical precision in different data types, gradient accumulation techniques, stochastic rounding, and Kahan summation. It explores the use of torch.compile for Triton kernels, FP16 matmuls with split-k, and accumulation in different data types. Additionally, the discussions cover PyTorch code compilation, mixed precision training strategies, BF16 considerations, and the integration of stochastic rounding. Various links are shared related to automatic mixed precision packages, stochastic rounding implementation, and autocast modes in PyTorch.
Collaborative AI Projects Discussion
The section provides insights into various collaborative AI projects and developments within the community. It highlights innovative uses of AI tools such as Lindy AI Agent for meeting briefings, OpenAI's sCMs boosting text-to-image speed, and ChatGPT's integration with Apple's AI. Additionally, Microsoft's OmniParser tool for structured data from UI screenshots and Cohere's multilingual models signify advancements in AI capabilities. Users discuss the potential of memory features in models, optimizations in AI systems, and the anticipation surrounding upcoming AI releases like GPT-4.5 and GPT-4o. The conversation emphasizes the need for effective prompt engineering and tailored interactions to enhance AI performance and user experience.
Interconnects - Nathan Lambert News
This section discusses various messages and tweets related to the interconnects. Topics include the launch of new models, discussions on AI advancements, critiques of Nobel AI awardees, and the introduction of new AI features. Different tweets and research reports provide insights into the latest developments in the AI field.
Exploring Attention in Tinygrad and Other Optimizations
A user inquired about the correct implementation of attention in Tinygrad and compared its performance with PyTorch, noting improvements with optimized function usage. Discussions highlighted the importance of using jitted functions for attention. Concerns were raised about memory allocation for tensor initialization impacting performance, with recommendations to allocate matrices directly on the GPU. Synchronization post-computation was emphasized for accurate benchmark timings, despite delays. Performance discrepancies in different versions of Tinygrad led to discussions on the importance of staying up-to-date. Suggestions to use kernel optimization flags like BEAM=4 were made for performance boost, although initial tests did not show significant improvements. Ongoing testing and adjustments were deemed necessary to find effective configurations for computational performance enhancement.
Social Networks and Footer
The section includes links to social networks such as Twitter and the newsletter subscription page. It also mentions finding AI news elsewhere. Additionally, the footer credits Buttondown as the platform used to start and grow the newsletter.
FAQ
Q: What are some recent advancements in AI hardware performance?
A: AI hardware performance is advancing rapidly with significant achievements reported by various companies.
Q: What AI models and releases have generated excitement in the AI community recently?
A: AI models like Stable Diffusion 3.5 and new multilingual models by Cohere are generating excitement in the AI community.
Q: What updates have been made to AI tools and applications by LangChain and Perplexity AI?
A: LangChain and Perplexity AI have offered updates to their AI tools and applications, providing enhanced features and productivity boosts.
Q: What are some recent AI company news and partnerships that have been announced?
A: Meta's release of quantized Llama 3.2 models and Snowflake's collaboration with ServiceNow for AI-driven innovation are some of the recent AI company news and partnerships announced.
Q: What insights were shared regarding the performance of Qwen 2.5 and Llama 3.2 models in the AI community?
A: Users in the AI community compared the performance of Qwen 2.5 and Llama 3.2 models, showcasing conflicting experiences and highlighting the nuances in their performance.
Q: How did Tensor Parallelism impact multi-GPU fine-tuning speed?
A: Upon implementing Tensor Parallelism for multi-GPU fine-tuning, epochs clocked in under 20 minutes, showcasing impressive training velocity.
Q: How does adjusting batch size across multiple GPUs affect global batch size?
A: Members confirmed that using batch_size = 6 across 8 GPUs results in a global batch size of 48, optimizing the distributed training process.
Q: What concerns were raised regarding dataloader performance bottlenecks?
A: Participants raised concerns about dataloader slowdown due to settings like num_processes=0 and insufficient pinned memory, suggesting optimizations to enhance training efficiency.
Q: What differences were highlighted between packed=True and packed=False training configurations?
A: Discussions highlighted mixed results between packed=True and packed=False training configurations, with packed data sometimes speeding up processes but producing unexpected responses.
Q: What was the inquiry about muP parameterizations progress?
A: A user inquired about the status of muP parameterizations for recipes, showing ongoing community interest in feature development and the necessity for concrete updates.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!