[AINews] nothing much happened today • ButtondownTwitterTwitter
Chapters
AI Twitter and Reddit Recaps
Innovations in LLM Reasoning and Inference Techniques
Center Stage
Migrating to Modern LLMChain Implementations
Model Variants and Fine-Tuning Strategies
Hardware Discussion
OpenRouter (Alex Atallah) - App Showcase
Chunk 8: CUDA MODE Discussions
Interconnects (Nathan Lambert) - ML Questions
Cohere Discussions
AI Discussion Highlights
AI Twitter and Reddit Recaps
The AI Twitter Recap highlighted advancements in AI models and performance, with examples like OpenAI's o1 Model, performance improvements in ChatGPT-4o, and comparisons between different model versions. The AI Reddit Recap from /r/LocalLlama discussed advancements in model compression and quantization, such as findings on the differences between bf16 and fp8 Llama models and the release of compressed Llama3.1-70B weights using AQLM+PV compression. This section provides insights into AI tools and applications, industry trends, and observations from the AI community.
Innovations in LLM Reasoning and Inference Techniques
Theme 2. Open-Source LLMs Closing the Gap with Proprietary Models
-
Hugging Face has optimized Segment Anything 2 (SAM 2) for on-device inference, allowing it to run on Mac and iPhone with sub-second performance. This development opens up possibilities for real-time segmentation tasks on mobile devices, potentially impacting augmented reality, image editing, and computer vision applications on edge devices.
-
Hugging Face is releasing Apache-licensed optimized model checkpoints for SAM 2 in various sizes, along with an open-source application for sub-second image annotation. They are also providing conversion guides for SAM2 fine-tunes like Medical SAM.
-
The developer plans to add video support and is open to suggestions for future features, indicating ongoing development and potential for expanded capabilities in the SAM 2 optimization project.
-
Users have shown interest in Apple optimizing other models, specifically mentioning GroundingDino, reflecting a demand for more on-device AI models optimized for Apple hardware.
Theme 3. Developments in LLM Reasoning and Inference Techniques
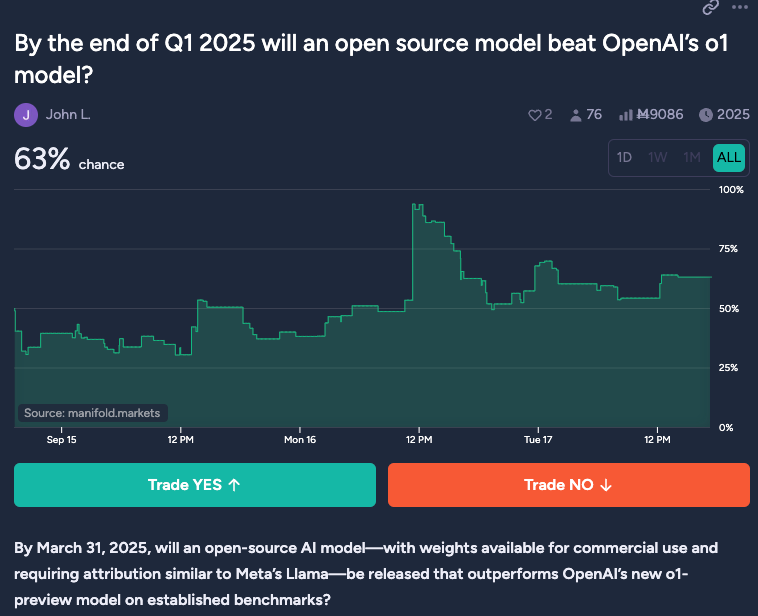
- Will an open-source model beat o1 by the end of Q1 2025? The speculation focuses on whether open-source language models could surpass OpenAI's GPT-4 by Q1 2025 using **
Center Stage
The Center Stage section features updates on various AI ventures and research ventures. From AI safety fellowships to Fourier transforms unveiling hidden state secrets, the community is actively engaged in exploring interpretability, alignment research, and the attention mechanism's role. Product manuals' visual data challenges are addressed by LlamaIndex, introducing a sophisticated indexing pipeline for effective navigation. The theme shifts to AI ventures in business and creativity, spotlighting events like Ultralytics' YOLO Vision 2024 and AdaletGPT's RAG chatbot for legal aid. Open Interpreter garners attention for its capabilities as beta tester slots become highly sought after.
Migrating to Modern LLMChain Implementations
Feedback suggested migrating from legacy LLMChain to newer models for better parameter clarity and streaming capabilities.
Newer implementations allow easier access to raw message outputs, stressing the importance of keeping updated.
Model Variants and Fine-Tuning Strategies
This section discusses the release of new model variants in Qwen 2.5, including sizes like 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B, highlighting stricter content filtering. It also covers the release of Mistral-Small-Instruct-2409 with 22B parameters and the challenges users face in installing Unsloth and fine-tuning models for specific JSON syntax. Additionally, the importance of Backus-Naur Form (BNF) in ensuring structural integrity in model outputs is emphasized.
Hardware Discussion
Discussions in this section revolve around hardware recommendations and setups for LM Studio. Members explore options like GPU recommendations, dual GPU setups, insights on used GPUs, Intel ARC performance for LLMs, and the criticality of VRAM in LLMs. Choosing between GPU models like 4090 and 4080 based on VRAM needs, the benefits of dual GPU setups, hunting for used GPUs in various markets, utilizing Intel ARC for LLMs, and the importance of VRAM thickness are key points discussed. Members exchange experiences and insights on GPU configurations and VRAM capacities, emphasizing the significance of adequate VRAM for powerful models.
OpenRouter (Alex Atallah) - App Showcase
OpenRouter has been successfully integrated into the GPT Unleashed for Sheets addon following a user's request, making it available for free. The addon includes innovative features like 'jobs', 'contexts', and 'model presets' to streamline prompt engineering and boost productivity. Recent September updates have enhanced the addon's functionality, adding support for Claude from Anthropic, increased UX/UI enhancements, and overall performance improvements. Users appreciate that the addon is free forever, supports numerous popular language models, and simplifies AI tool building, offering massive productivity boosts and effective tracking of results and API calls.
Chunk 8: CUDA MODE Discussions
BitNet's Packing Efficiency:
- Efficiently packing 5 ternary values in an 8-bit space discussed.
- Code shared for packing process optimization without modulo and division.
SK Hynix In-Memory Computing:
- Advancements in in-memory computing for LLM inference presented at Hot Chips 2024.
- Utilizing AiMX-xPU and LPDDR-AiM technologies to reduce power consumption and increase efficiency.
Lookup Tables Implementation:
- Potential benefits of Lookup Tables (LUT) for enhancing packing method efficiency explored.
- Integration with packed values and need for further examination highlighted.
Custom Silicon Development:
- Discussion on Deepsilicon focusing on AI computations with significantly less RAM.
- Viability concerns raised, showcasing ongoing interest in innovative AI computing.
BitNet Implementation Queries:
- Debate on 2-bit implementation from BitNet paper impacting GPU runtime performance.
- Acknowledgment of need for deeper understanding of embedding, LM-head, and quantization strategies in the paper.
Links Mentioned:
- SK Hynix AI-Specific Computing Memory Solution AiMX-xPU at Hot Chips 2024
- deepsilicon
- Tweet from Diana (@sdianahu) about Deepsilicon's achievements
Interconnects (Nathan Lambert) - ML Questions
Research indicates that allowing transformers to utilize 'chain of thought' or 'scratchpad' enhances computational power, with implications for solving reasoning problems. Best practices for visualizing attention matrices in QA settings are discussed to demonstrate connections between questions and facts. The Alpha Code website's interactive feature shows the most attended tokens, improving user understanding of attention relationships in generated responses. Referring to the attention rollout paper can provide insights into different definitions of 'most attended'.
Cohere Discussions
Cohere launched beta Safety Modes in Chat API, focusing on user safety and guard rails. They also discussed market strategy, incorporating local languages, and a new candidate for a Japanese language role. Questions arose about fine-tuning models and dataset management. Cohere API section highlighted issues with Sagemaker and support recommendations. In the DSPy channels, discussions involved GPT-4 Vision API wrapper introduction, interest in contributions, documentation needs, and program flexibility inquiries.
AI Discussion Highlights
This section highlights various discussions from different AI-related channels on Discord. Members explored topics like image compositing techniques, post-processing for image quality, the use of Nouswise in the creative process, Whisper speech technology support, and computational resource support for projects like StyleTTS-ZS. Additionally, discussions in other channels covered topics such as open interpreter updates, beta testing inquiries, tool use podcasts, and RISC-V support inquiries. These conversations shed light on the diverse interests and innovative projects being pursued within the AI community.
FAQ
Q: What advancements were highlighted in AI models and performance on Twitter and Reddit recaps?
A: The Twitter recap highlighted advancements in AI models like OpenAI's o1 Model and performance improvements in ChatGPT-4o. The Reddit recap from /r/LocalLlama discussed advancements in model compression and quantization, such as findings on bf16 and fp8 Llama models.
Q: What developments were mentioned for the SAM 2 model by Hugging Face in the essai?
A: Hugging Face optimized Segment Anything 2 (SAM 2) for on-device inference, allowing it to run on Mac and iPhone with sub-second performance. They released Apache-licensed optimized model checkpoints for SAM 2 in various sizes and provided an open-source application for sub-second image annotation.
Q: What discussions took place around open-source language models potentially surpassing GPT-4 by Q1 2025?
A: The speculation focused on whether open-source language models could surpass OpenAI's GPT-4 by Q1 2025.
Q: What insights were shared regarding AI tools and applications in the essai?
A: Insights were shared about industry trends, advancements in AI tools, developments in reasoning and inference techniques, and the community's observations on the AI landscape.
Q: What new model variants were released in Qwen 2.5 according to the essai?
A: New model variants were released in Qwen 2.5, including sizes like 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B with stricter content filtering.
Q: What were the main points discussed in the BitNet's Packing Efficiency section of the essai?
A: The essai discussed efficiently packing 5 ternary values in an 8-bit space and shared code for packing process optimization without modulo and division.
Q: What advancements were presented in SK Hynix In-Memory Computing at Hot Chips 2024?
A: Advancements in in-memory computing for LLM inference were presented at Hot Chips 2024, utilizing AiMX-xPU and LPDDR-AiM technologies to reduce power consumption and increase efficiency.
Q: What was highlighted regarding Lookup Tables (LUT) implementation in the essai?
A: The essai explored the potential benefits of Lookup Tables for enhancing the efficiency of packing methods and integration with packed values.
Q: What was the focus of the discussions around Custom Silicon Development in the essai?
A: The essai focused on discussions around Deepsilicon, emphasizing AI computations with significantly less RAM and viability concerns regarding innovative AI computing.
Q: What were the key points discussed in the OpenInterpreter section of the essai?
A: The essai discussed the integration of OpenRouter into the GPT Unleashed for Sheets addon, featuring innovative features for prompt engineering and productivity, emphasizing free availability and support for various language models.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!