[AINews] MM1: Apple's first Large Multimodal Model • ButtondownTwitterTwitter
Chapters
AI Twitter Recap and Summaries
Function Calling in AI Models
LAION Discord
Interconnects (Nathan Lambert) Discord
Discussion on AI Models and Tools
Interactions and Discussions on Apple's LLM Models and Hardware
AI Research Discussions
Latest AI Discoveries and Advancements
AI Community Discussions
Axolotl Framework Updates and Optimizations
Discussion on Various Topics in Discord Channels
Concerns and Developments in AI Community
AI Twitter Recap and Summaries
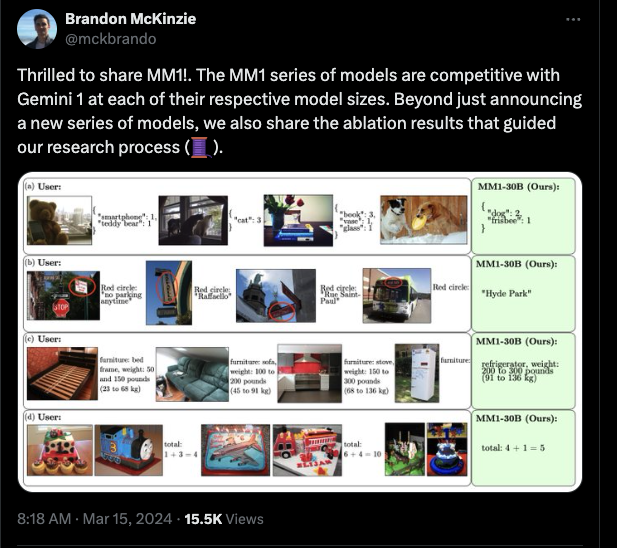
This section covers various topics related to AI progress, new models and datasets, open source and reproducibility, tools and frameworks, as well as memes and humor shared on Twitter. It includes insights from prominent figures like Yann LeCun discussing the requirements for human-level AI, discussions on large language models like MM1 and Command-R, hardware optimizations, AI model interpretability, prompt engineering, open-source AI frameworks, AI security and privacy concerns, emerging AI platforms and tools, and enhancements in function calling and JSON mode.
Function Calling in AI Models
Discussions highlighted the challenges of using JSON mode effectively in complex conversations, possibly requiring content summarization or trimming. New developments in model fine-tuning were showcased with the d-Qwen1.5-0.5B student model surpassing its base model's benchmarks and the Genstruct 7B model being tested for generating instruction datasets. Modi opens the office's new version of the net framework efforts aim.
LAION Discord
Discord Summary
- GPU Assist Wanted: Collaborators with 3090s or 4090s GPUs are needed for captioning work; contact via direct message.
- M3 Max Memory Push: Discussions on utilizing over 96GB memory in a 128G M3 Max macOS system for optimization with simpletuner.
- Prompt Augmentation Tactics Shared: Highlight of a 77M T5 model for prompt augmentation in image generation and the introduction of DanTagGen for autocompleting tags.
- EU Moves on AI Regulation: European Parliament adoption of the Artificial Intelligence Act for AI safety and fundamental rights adherence.
- IEEE Paper Vanishes: Removal of the 45th IEEE Symposium on Security and Privacy from accepted papers page and its potential impact on an individual named Ben.
- TryOnDiffusion Opens Closets: Announcement of open-source TryOnDiffusion implementation based on "A Tale of Two UNets" methodology on GitHub.
Interconnects (Nathan Lambert) Discord
LLM Secrets Possibly Exposed
New research suggests that hidden details of API-protected Large Language Models, like GPT-3.5, might be leaked, unveiling model sizes through the softmax bottleneck. Discussion highlights a paper by Carlini et al. expressing skepticism about the estimation accuracy and feasibility of a 7B parameter model.### Exploring Model Sophistication Techniques Engineers are theorizing over advanced model techniques like 'mega distillation sauce' and token-critical mixtures, noting the impact of early tokens on performance in tasks such as solving math problems.### Evolving Safety Classification AI safety discussion references a paper on agile text classifiers, detailing how large language models tuned with small datasets can effectively adapt to safety policies and enhance content moderation.### Anticipating AI Advancements for Ultrapractical Uses Excitement over the development of Gemini for managing ultra-long contexts and hopes for AI tools to automatically summarize new academic papers citing one's work. The conversation covers the limitations of prompt engineering and the community's eagerness for more intuitive prompting suggestions akin to 'getting warmer or colder' search suggestions.### Dispelling Myths and Pondering Thought Leaders Dispelling GPT-4.5 release rumors and discussions around Yann LeCun's skeptical take on language models. Shared tweet provokes conversations about technical discourse with an entertaining spin.
Discussion on AI Models and Tools
-
Schema Confusion for JSON Mode: Users discussed challenges with using JSON mode in AI models. Generating JSON output in complex conversations required explicit user prompt requests, and even after fixing schema tags, issues persisted, hinting at the need for summarization or trimming for effective JSON extraction.
-
Exploring Genstruct 7B's Capabilities: Users engaged with the Genstruct 7B model for generating instruction datasets. A user planned to test with text chunks and shared a repository with examples on how to use it, emphasizing the need for both title and content for effective results.
-
Open Source Code Interpreter Pursuits: Discussions highlighted the lack of open-source GPT code interpreters for tasks like CSV handling. While the open-interpreter on GitHub was mentioned, it was noted to be more suited for sending instructions rather than interpreting code.
-
Seeking Perplexity Solutions for LLaMA: A user sought advice on computing perplexity for LLaMA models, mentioning potential issues with a Kaggle notebook's guidance on perplexity calculation not yielding expected results, indicating possible process or model-related issues.
Interactions and Discussions on Apple's LLM Models and Hardware
This section covers conversations related to LM Studio feedback, confusion over model support in llama.cpp, discussions on optimizing Apple's hardware for LLMs, including using the M2 Macbook, tweaking VRAM settings, evaluating GPUs, and monitor choices. Additionally, it delves into technical troubleshooting with AMD GPUs, discussions on RTX GPUs, career progressions within the tech industry, and AI model compressions. The discourse also touches on the Perplexity AI platform, highlighting interactions, technical queries, and enhancements. Lastly, insights into Eleuther discussions on gaming AI, FPS development challenges, and AI's gaming capabilities are outlined, providing a comprehensive view of the varied discussions and topics in the AI community.
AI Research Discussions
Debating the Efficacy of AI Detectors:
- Questioned the reliability of AI content detectors in distinguishing between human and AI-generated content, highlighting the challenges in differentiating them.
Content Watermarking Discussed:
- Discussed the potential and limitations of cryptographic watermarking for AI outputs, with skepticism about efficiency and implications for model utility.
New Advances in AI Reasoning:
- Mentioned a new technique called Quiet-STaR to improve language models' ability to 'think ahead' before generating tokens.
Contours of GPT-turbo Explored:
- Analyzed a paper on the commercialization of large language models and the estimation of valuable information from API queries.
Discourse on Tokenizing Numbers in LLMs:
- Explored the effect of tokenizing numbers left-to-right versus right-to-left on a model's arithmetic capabilities and discussed exploiting tokenizing strategies for enhanced performance.
Latest AI Discoveries and Advancements
In this section, various new AI advancements and findings are highlighted. These include the benefits of using pseudocode to prompt Large Language Models, the integration of SAP HANA Vector Engine with LangChain for improved AI applications, the introduction of Mamba-Chat - a chatbot using state-space model architecture, DeepMind's introduction of Robotic Transformer 2 for robotic vision-language-action modeling, and Hugging Face's Kyle - a Unity-based training environment for ragdoll training with advanced vision capabilities. Additionally, there are discussions on various topics such as open LLMs, refactoring in VS Code, privacy-focused front end repositories, and AI's application in navigating open records laws. These findings and discussions are insightful in showcasing the latest trends and developments in the AI field.
AI Community Discussions
Latent Space ▷ #ai-general-chat
- Potential OpenAI Security Breach Discussed: A Post Mortem on a security issue that occurred at OpenAI detailed how requests might have been made on behalf of another account. More information is provided in the documentation on GitHub Gist.
- State of Sparse Universal Transformers: Insights were shared on weight sharing for Sparse Universal Transformers and the development of ScatterMoE for fast Mixture-of-Experts for attention.
- The AI Development Platform with Affordable Pricing: Deci AI launched the Deci AI Nano model and an associated development platform priced at $0.1 per 1M tokens. Additional marketing blog and technical tutorials are linked.
- Prompt Augmentation to Enhance Creative AI: A discussion on prompt augmenters noted the success of a 77M T5 model in expanding prompts, outperforming larger LLMs in quality and prompt alignment. Full details are available at 'Prompt Augmentation'.
- AMD's Ray Tracing Move to Open Source: AMD made their HIP-Ray Tracing RT code open-source, sparking discussions on the open-source ecosystem.
AI Community Discussions
- Tuning in to Transformers: An episode featuring an interview on music generation using transformers is live on YouTube titled 'Making Transformers Sing'.
- Paper Club Gathering Alert: The Paper Club is reviewing the 'A Comprehensive Summary Of Large Language Models' paper.
Latent Space ▷ #llm-paper-club-west
- Curiosity About Supervised Fine-Tuning (SFT): Interest was shown in Supervised Fine-Tuning on negative pairs.
- Decoding the Rationale Behind Attention: Discussion on the attention mechanism in transformers.
- Untangling the Concept of Parallelization: Clarification on parallelization in transformer models.
- Understanding Transformer Motivations: Importance of understanding design choices in transformers.
- Appreciation for Learning Experience: Participants express gratitude for insights on Large Language Models.
Latent Space ▷ #ai-in-action-club
- Passive Participation in IRL Meetings: Mention of passive participation in an IRL meeting and upcoming in-depth blog posts.
- Anticipation of In-Depth Content: Members hint at upcoming detailed blog posts.
- Nuisance of Web Interfaces for RAG: Reported issues with RAG web interface stability.
- Sharing Useful Resources on RAG: Resource link on advanced RAG techniques shared.
- Resource Compilation Document Shared: Comprehensive Google Sheets document compiling resources.
OpenAI ▷ #ai-discussions
- Microsoft Employee Fixes Typo After Community Ping: Issue reported and fixed with the help of Bing VP.
- Stumped by Repeated Morphemes: Challenges with GPT-3.5 on generating repeated morphemes.
- Anticipation for OpenAI Updates: Discussion on expectations for OpenAI updates and their impact.
- Delegating Tasks to Domain-Specific AIs: Discussion on creating a multi-tiered AI system with a 'central brain'.
- ChatGPT Team and Privacy Concerns: Questions on ChatGPT team capabilities and privacy.
OpenAI ▷ #gpt-4-discussions
- wesego: Hi, having that problem right now.
OpenAI ▷ #prompt-engineering
- Comma Confusion in Number Formats: Discussions on using commas as decimal separators in number formats.
- Considering Global Number Formats: Addressing issues with cultural number formats.
- Seeking Guidance on GPT-3 Prompt Architecture for Classification: Sharing efforts using GPT-3 for classification tasks.
- Balance is Key in Prompt Design: Advice on prompt structure for optimal results.
OpenAI ▷ #api-discussions
- Localization Woes in Decimal Representation: Discussion on localization issues with commas and decimal points in numbers.
- Model Cultural Flexibility: Adjusting for cultural differences in number formats.
- Optimizing Classification Prompt Architecture: Queries on refining a prompt setup for classification tasks.
- Efficient Context Usage for Prompts: Suggestions for optimizing context usage in prompts.
OpenAccess AI Collective (axolotl) ▷ #general
- Discussing Finetuning Large Models on Single GPUs: Enthusiasm expressed for finetuning techniques on single GPUs.
Axolotl Framework Updates and Optimizations
In this section, discussions around Axolotl framework updates and optimizations were highlighted. Topics covered include member experiences with model training and hardware compatibility, debates on training formats, user guidance for data format and conversion, differences between Axolotl and LoRA fine-tuning methods, ScatterMoE optimizations promising advancements, seeking clarifications on ScatterMoE, challenges and recommendations for post-training implementations, suggestions for upgrading PyTorch for compatibility, and confirmation of tool versions. Links to relevant resources and discussions on these topics were also shared for further reading and exploration.
Discussion on Various Topics in Discord Channels
The section covers a range of discussions from different Discord channels. Members share concerns about the compatibility of ring attention, difficulties in finding missing code, and confusion over ring flash attention. Additionally, topics include a lawsuit against a former Meta executive, Langchain's release rush and call for community feedback, challenges with language models, debates on the usefulness of LLM agents, and the integration of LangChain with SAP HANA. The section also touches on topics like prompt augmentation, virtual try-on technology, fast decoding research, AI law regulation, and the KPU framework's performance compared to GPT-4. There are also reflections on personal projects, content moderation challenges with specific images, and skepticism towards KPU's benchmarks.
Concerns and Developments in AI Community
The chunk discusses concerns over practical efficiency in KPU's comparative analysis and mentions a pattern seen in Claude 3's release. Additionally, a chat thread in Skunkworks AI talks about an upcoming paper on improved training methods, seeking resources for scaling, and collaborations for testing the new method. The Datasette - LLM section covers various tools and platforms for prompt engineering, while Interconnects delves into discussions on API-protected LLMs and safety filtering by model providers. The section on DiscoResearch highlights challenges faced with DiscoLM models and introduces new evaluation tasks and additions in the GermanQuAD task.
FAQ
Q: What are the key topics covered in the essai regarding AI progress?
A: The key topics covered in the essai regarding AI progress include new models and datasets, open source and reproducibility, tools and frameworks, AI security and privacy concerns, advancements in AI platforms and tools, and enhancements in function calling and JSON mode.
Q: What is the significance of the discussions on JSON mode in AI models?
A: The discussions on JSON mode in AI models highlight the challenges faced in generating JSON output in complex conversations, emphasizing the need for explicit user prompt requests and possible requirements for content summarization or trimming for effective JSON extraction.
Q: What were some of the highlighted advancements in model fine-tuning showcased in the essai?
A: Advancements in model fine-tuning showcased in the essai include the d-Qwen1.5-0.5B student model surpassing its base model's benchmarks and the testing of the Genstruct 7B model for generating instruction datasets.
Q: What are some of the discussions related to AI safety and AI advancements mentioned in the essai?
A: Discussions related to AI safety and advancements in the essai include agile text classifiers for AI safety, trends in model sophistication techniques, and anticipations for practical uses of AI tools such as Gemini for managing ultra-long contexts.
Q: What were some of the topics explored in relation to AI reasoning and technology advancements mentioned in the essai?
A: The topics explored in relation to AI reasoning and technology advancements in the essai include the utilization of pseudocode for prompting LLMs, integration of SAP HANA Vector Engine with LangChain, and the introduction of AI tools like Mamba-Chat and Robotic Transformer 2.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!