[AINews] Mamba-2: State Space Duality • ButtondownSummaryTwitterTwitter
Chapters
AI News: Mamba-2 State Space Duality
AI Twitter Recap
Modular (Mojo 🔥) Discord
OpenInterpreter
AI Community Discords
Unsloth AI Chat Highlights
Unsloth AI Showcases and Collaborations
Perplexity AI Users and API Guidance
CUDA MODE Conversations
PyTorch Performance Documentation Review
World Simulation and Scenario Exploration
LLM Finetuning Workshop Highlights
LLM Finetuning Discussions
LLM Finetuning (Hamel + Dan) Career Questions and Stories
Eleuther General
OpenRouter Playground
Discussion on Recent AI Events
Interconnects (Nathan Lambert) Latest News
Mozilla AI, DiskoResearch, Datasette, AI21 Labs, MLOps @Chipro Updates
AI News: Mamba-2 State Space Duality
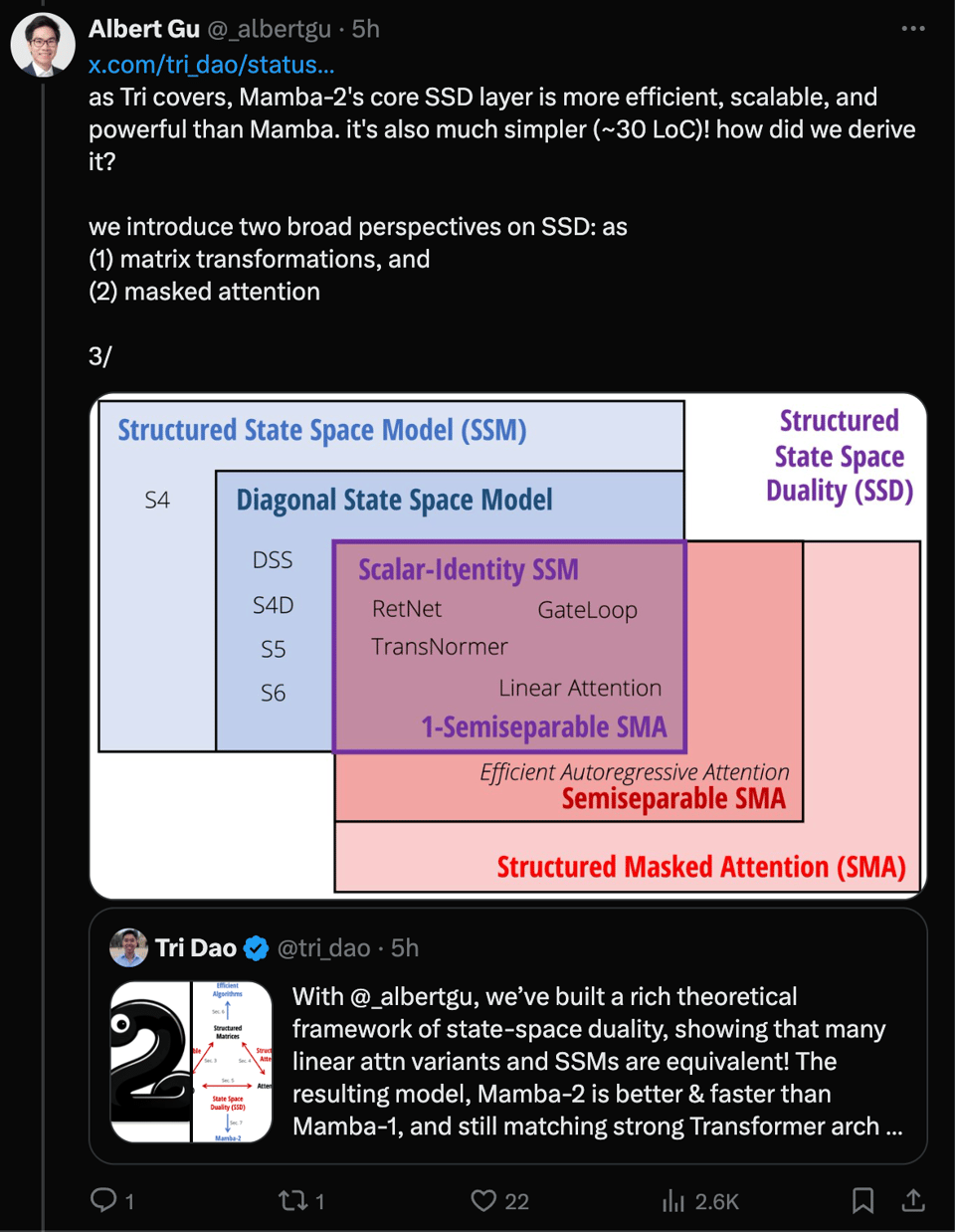
The latest AI News email covers the release of Mamba-2, a new model developed by the coauthors of Mamba. The blog posts on FineWeb Technical Report and the improvements it offers are discussed. The core difference between Mamba and Mamba-2, the Quadratic Mode (Attention) versus Linear Mode (SSMs), is highlighted. The email also includes a recommendation to read the blog developed in four parts, covering the understanding, efficiency, theory, algorithm, and systems of Mamba-2.
AI Twitter Recap
AI and Machine Learning Research
- Mamba-2 State Space Model: Albert Gu and Tri Dao introduced Mamba-2, a state space model (SSM) that outperforms Mamba and Transformer++ in perplexity and wall-clock time. It presents a framework connecting SSMs and linear attention called state space duality (SSD). Mamba-2 has 8x larger states and 50% faster training than Mamba. (Aranko Matsuzaki and Akhaliq)
- FineWeb and FineWeb-Edu Datasets: Clement Delangue highlighted the release of FineWeb-Edu, a high-quality subset of the 15 trillion token FineWeb dataset, created by filtering FineWeb using a Llama 3 70B model to judge educational quality. It enables better and faster LLM learning. Karpathy noted its potential to reduce tokens needed to surpass GPT-3 performance.
- Perplexity-Based Data Pruning: Akhaliq shared a paper on using small reference models for perplexity-based data pruning. Pruning based on a 125M parameter model's perplexities improved downstream performance and reduced pretraining steps by up to 1.45x.
- Video-MME Benchmark: Akhaliq introduced Video-MME, the first comprehensive benchmark evaluating multi-modal LLMs on video analysis, spanning 6 visual domains, video lengths, multi-modal inputs, and manual annotations. Gemini 1.5 Pro significantly outperformed open-source models.
AI Ethics and Societal Impact
- AI Doomerism and Singularitarianism: Yann LeCun and François Chollet criticized AI doomerism and singularitarianism as 'eschatological cults' driving insane beliefs, with some stopping long-term life planning due to AI fears. Yann LeCun argued they make people feel powerless rather than mobilizing solutions.
- Attacks on Dr. Fauci and Science: Yann LeCun condemned attacks on Dr. Fauci by Republican Congress members as 'disgraceful and dangerous'. Fauci helped save millions but is vilified by those prioritizing politics over public safety. Attacks on science and the scientific method are 'insanely dangerous' and killed people in the pandemic by undermining public health trust.
- Opinions on Elon Musk: Yann LeCun shared views on Musk, liking his cars, rockets, solar/satellites, and open source/patent stances, but disagreeing with his treatment of scientists, hype/false predictions, political opinions, and conspiracy theories as 'dangerous for democracy, civilization, and human welfare'. He finds Musk 'naive about content moderation difficulties and necessity' on his social platform.
AI Applications and Demos
- Dino Robotics Chef: Adcock Brett shared a video of Dino Robotics' robot chef making schnitzel and fries using object localization and 3D image processing, trained to recognize various kitchen objects.
- SignLLM: Adcock Brett reported on SignLLM, the first multilingual AI model for Sign Language Production, generating AI avatar sign language videos from natural language across eight languages.
- Perplexity Pages: Adcock Brett highlighted Perplexity's Pages tool for turning research into articles, reports, and guides that can rank on Google Search.
- 1X Humanoid Robot: Adcock Brett demoed 1X's EVE humanoid performing chained tasks like picking up a shirt and cup, noting internal updates.
- Higgsfield NOVA-1: Adcock Brett introduced Higgsfield's NOVA-1 AI video model allowing enterprises to train custom versions using their brand assets.
Modular (Mojo 🔥) Discord
Users on the Modular (Mojo 🔥) Discord channel reported issues with the Mojo language server crashing in VS Code derivatives, particularly on M1 and M2 MacBooks, leading to discussions on solutions and optimizations. There were discussions surrounding Mojo's maturity, its progress, and open-source contributions, as detailed in the Mojo roadmap and blog announcements. Additionally, conversations included the potential of Mojo in data processing and networking using frameworks like DPDK and liburing. Members also delved into the implementation of the forward pass in the Max engine and the lack of documentation for backward calculations, alongside excitement over conditional conformance capabilities in Mojo to enhance the standard library's functions.
OpenInterpreter
Efforts to integrate Whisper or Piper into Open Interpreter (OI) are underway in order to reduce verbosity and increase speech initiation speed. Clarifications were made about 'agent-like decisions' within OI, leading to a specific section in the codebase. Discussions revolved around a need for marketing efforts for Open Interpreter and the challenges of running Gemini on the platform. Additionally, there are ongoing discussions on creating an app to link the OI server to iPhone, with confirmed TTS functionality on iOS and an Android version in development. Lastly, Loyal-Elephie is briefly mentioned without context by a user.
AI Community Discords
This section covers discussions and developments from various AI-related Discord channels. Engineers are exploring ways to enhance model performance, integrate new tools like Paddler, address server issues, and strive for uniformity in model interfaces despite unique challenges. The 'DiscoResearch' Discord touches on Spaetzle models and anticipation for the replay buffer implementation. In the 'LLM (@SimonW)' Discord, challenges with Claude 3 and model queries are discussed. The 'AI21 Labs (Jamba)' Discord compares Jamba Instruct to Mixtral and delves into the challenges of function composition in AI models. The 'MLOps @Chipro' Discord highlights the AI4Health Medical Innovation Challenge Hackathon/Ideathon. Each Discord presents a unique perspective on AI advancements and challenges in the field.
Unsloth AI Chat Highlights
The Unsloth AI Discord channel had various discussions on topics like error fixes, AI model limitations, and training techniques. Members shared insights on challenges like running Phi 3 models on GTX 3090, concerns about open-source AI models, and methods to train models to avoid irrelevant prompts. Additionally, the group discussed helpful resources, documentation updates, and GPU compatibility for Unsloth. The community also shared tips on resolving installation issues and improving model performance.
Unsloth AI Showcases and Collaborations
Experimenting with Ghost Beta Checkpoint:
The experimentation continues with a checkpoint version of Ghost Beta in various languages including German, English, Spanish, French, Italian, Korean, Vietnamese, and Chinese. It is optimized for production and efficiency at a low cost, with a focus on ease of self-deployment.
Evaluating Language Quality:
GPT-4 is used to evaluate the multilingual capabilities of the model on a 10-point scale, but this evaluation method is not official yet. Trusted evaluators and community contributions will help refine this evaluation for an objective view.
Handling Spanish Variants:
The model employs a method called 'buffer languages' to handle regional variations in Spanish during training. The approach is still developing, and the specifics will be detailed in the model release.
Mathematical Abilities and Letcode:
The model's mathematical abilities are showcased with examples on the Letcode platform. Users have been encouraged to compare these abilities with other models on chat.lmsys.org.
Managing Checkpoints for Fine-Tuning:
Users discussed saving checkpoints to Hugging Face (HF) or Weights & Biases (Wandb) for continued fine-tuning. The process includes setting 'save_strategy' in 'TrainingArguments' and 'resume_from_checkpoint=True' for efficient training management.
Perplexity AI Users and API Guidance
- Users leverage Perplexity AI for a variety of searches: Users shared search results like AI transforming lives, Israel-Gaza war, and Preventing spam.
- Exploration of Perplexity Pages feature: Members created and shared pages on topics like Blade Runner and Simple Solidity Auction.
- AI tool ideas and improvements: Users discussed ideas for AI tools, including utilizing live data from Waze.
- Discussion on sensitive topics: Delicate topics like the Israel-Gaza war were tested on Perplexity AI.
- Diverse content sharing: Various topics like Evariste Galois and cold weather benefits were shared.
Perplexity AI #pplx-api
- New API Users Seek Model Guidance: New users questioned model performance for diverse use cases.
- Small Models vs Large Models: Differences between smaller and larger models were highlighted.
- Interest in TTS API: Inquiries were made about the possibility of a TTS API from Perplexity using services from 11Labs.
Supported Models: no description found
CUDA MODE Conversations
CUDA MODE ▷ #torchao (15 messages🔥):
- TorchAO: Discussions on integrating TorchAO quantization support with the LM Evaluation Harness, potential API expansions, UInt4Tensor generalization, and effectiveness of quantization and sparsity.
CUDA MODE ▷ #ring-attention (4 messages):
- Clarity on 'hurn model' confusion, RULER graphs for reference.
CUDA MODE ▷ #off-topic (36 messages🔥):
- Various discussions including AI skepticism in Berlin, PhD position hunt in Germany, graduate vs. industry roles, and noteworthy research groups like Dan Alistarh Group in Austria.
CUDA MODE ▷ #hqq (3 messages):
- Inquiry on model inference, blogpost announcement on Whisper model quantization.
CUDA MODE ▷ #llmdotc (504 messages🔥🔥🔥):
- Resolving 200GB dataset upload issues, FineWeb tokenization challenges, LayerNorm optimization proposal, CI and memory management cleanup, and integration and future proofing refactor.
CUDA MODE ▷ #bitnet (52 messages🔥):
- Discussions on quantization kernels, ongoing project roadmap, performance benchmarks, GitHub collaboration and permissions, and unit type implementation issues.
PyTorch Performance Documentation Review
The PyTorch docathon scheduled from June 4 to June 16 aims to improve performance-oriented documentation. Concerns were raised about outdated documents like the Performance Tuning Guide and the suggestion to update the documentation to remove mentions of 'torchscript' in favor of 'compile'. There is an emphasis on explaining the need for custom kernels and clear instructions on how to integrate them into PyTorch workflows.
World Simulation and Scenario Exploration
Does Claude remember previous chats?: Members questioned whether Claude retains information across sessions and whether it counts against the total token limit. They clarified that you can reload previous context but the bot does not maintain long-term memory automatically.
Worldsim explores Ukraine-Russia scenario: Some users are simulating the current Ukraine-Russia conflict in Worldsim to test various escalation scenarios and potential outcomes. They noted the ease with which Worldsim fills in accurate details, suggesting interest in a full WorldSim WarGaming mode.
CRT-terminal frontend project revealed: The frontend project used for the Worldsim console was identified as CRT-terminal on GitHub. However, a switch to an in-house solution is planned due to compatibility issues with mobile input.
Text duplication glitch in Worldsim: Members reported a glitch where text duplicates when writing prompts in the Worldsim console. The team is currently working on fixing this issue.
Accessing and retrieving chat logs: Users asked about obtaining copies of their chat logs within Worldsim and navigating back to previous chats. They were informed about the usage of commands !list and !load to manage chat history.
LLM Finetuning Workshop Highlights
- Newsletter Summarizer Proposal: One member proposed a Newsletter summarizer using an LLM to consolidate multiple newsletters into one summary. Emphasis was placed on fine-tuning for personalization and the potential to convert text summaries into podcast episodes.
- Questions on Dataset Creation: Another member, working on a similar newsletter summarization project, inquired about the dataset creation process.
- Technical Documentation Aid with LLMs: Using LLMs to generate technical documentation was discussed. This included detailing function attributes, limitations, and example usages to save time in understanding code-bases.
- Assisting with Legal Documents: LLMs could potentially help in filling out forms and documents, specifically legal ones, by fast-tracking the process through fine-tuning on relevant documents.
- Course Forum Response Generation: Another member suggested using LLMs for generating responses on course forums. The model would be trained on course materials and historical responses, with DPO used to refine response quality.
LLM Finetuning Discussions
This section covers various discussions related to LLM Finetuning from the daily updates in the community. These discussions include challenges in setting up different models, comparisons between tools like FastHTML and FastUI, issues with MacOS compatibility and Docker use, customization of Axolotl prompt strategies, insights into inference mechanics and model shard sizes in Accelerate, sharing and hosting Gradio apps, and troubleshooting issues with Mistral7B model downloads and Hugging Face token authentication. Additionally, there were talks about credit allocations, inquiry on model evaluations using a graded scorer, troubleshooting form submissions, and expressions of excitement about upcoming events and meetups.
LLM Finetuning (Hamel + Dan) Career Questions and Stories
- Historian Transitions to Tech: User shares journey from history to ML role, emphasizing importance of courses like fastai and Launch School.
- Graph Enthusiast Leverages Layoff: Dan transitions from accounting to data science due to Neo4j use in Panama Papers, now works on graph algorithms at Neo4j.
- Math Programming Obsession: Laith progresses from university courses to consulting and deep learning, credits Radek Osmulski's blog for ML learning.
- Reddit Engineer Seeks ML Pivot: Backend engineer at Reddit seeks advice on moving from ML inference stacks to product creation.
- Consultancy Idea for ML and Low-level Engineering: Niche consultancy model suggested for optimizing ML model inference in C++ or Rust.
Eleuther General
Connection Issues and Outages:
- Many users reported 504 errors and gateway timeouts while trying to connect to the API. Admins acknowledged ongoing issues with their database provider and promised to resolve them soon.
Regional Variability in API Functionality:
- Users located in Germany and the US noted that the OpenRouter API was functioning fine, while users in Southeast Asia and other regions continued experiencing issues.
OpenRouter Credits and Payments Confusion:
- A user reported an issue with OpenRouter credits after paying with a different wallet. The problem was resolved by realizing the credits were attributed to the initial wallet logged in.
Request for Enhanced Uptime Monitoring:
- Users like cupidbot.ai suggested adding provider-specific uptime statistics to the uptime chart to hold providers accountable for service reliability.
Questions about Model Performance and Configuration:
- Multiple users raised questions about the addition of new LLMs, rate limits on specific models like Gemini-1.5-Pro, and the quantization levels offered by providers.
OpenRouter Playground
The OpenRouter platform allows users to access numerous language models from various providers, offering options to prioritize either price or performance. With a standardized API, users can easily switch between models or providers without code changes. The platform evaluates model effectiveness based on real-world usage data rather than just benchmarks. Users can experiment with different models on the OpenRouter Playground to make informed decisions for their specific needs.
Discussion on Recent AI Events
The section discusses various events and incidents in the AI community, such as Dario Amodei being named as a Time's Top 100 influential person and the delay in releasing the powerful chatbot Claude. There are also conversations surrounding the alleged stealing incident around llama3-v reported on GitHub. Additionally, the section covers announcements and updates related to AIEWF speakers, AI industry support, and exciting keynotes. Technical difficulties with video streams and solutions provided, as well as discussions on LangChain, including using RAG with historical data, debate on agent structure for a chatbot, and comparison between LangChain and OpenAI agents. There are also updates on LangChain tools and functions, discussions on personal shopper with vector stores, and requests for LangChain updates. The section concludes with tutorials on exploring LLMs with Hugging Face and LangChain, building a Discord bot with Langchain and Supabase, and other related topics.
Interconnects (Nathan Lambert) Latest News
The section provides updates on various topics such as security incidents at Hugging Face, Phi-3 models performance, Llama 3V model accusations, and discussions surrounding Chris Manning. There are also mentions of ongoing developments in OpenInterpreter, including custom speech implementations and querying technical issues.
Mozilla AI, DiskoResearch, Datasette, AI21 Labs, MLOps @Chipro Updates
Mozilla AI program is accepting applications focusing on Local AI, offering up to $100,000 in funding, mentorship, and community support. Discussions in Discord channels include topics such as stateful load balancers, JSON schema optimizations, OpenAI-compatible chat completion, and model compatibility. The DiscoResearch channel talks about a replay buffer method, German handwriting recognition models, and different Spaetzle models. Datasette channel discusses issues with Claude 3 lacking a tokenizer, troubleshooting Nomic Embed Model, and switching to a new Sentence Transformers Plugin. AI21 Labs compares Jamba Instruct with GPT-4 and discusses the limitations of ML/DL models in function composition. Finally, MLOps @Chipro announces the AI4Health Medical Innovation Challenge Hackathon/Ideathon offering over $5k in prizes to develop innovative AI solutions for healthcare challenges.
FAQ
Q: What is Mamba-2 and how does it differ from Mamba?
A: Mamba-2 is a state space model (SSM) introduced by Albert Gu and Tri Dao that outperforms Mamba and Transformer++ in perplexity and wall-clock time. One of the core differences between Mamba and Mamba-2 is the Quadratic Mode (Attention) versus Linear Mode (SSMs), with Mamba-2 presenting a framework connecting SSMs and linear attention called state space duality (SSD). Mamba-2 has 8x larger states and is 50% faster in training compared to Mamba.
Q: What is the FineWeb-Edu dataset and how does it improve learning?
A: FineWeb-Edu is a high-quality subset of the 15 trillion token FineWeb dataset, created by filtering FineWeb using a Llama 3 70B model to judge educational quality. It enables better and faster learning for Large Language Models (LLMs) like Gemini, offering the potential to reduce the tokens needed to surpass GPT-3 performance.
Q: What is Perplexity-Based Data Pruning and how does it improve performance?
A: Perplexity-Based Data Pruning, as shared by Akhaliq, involves using small reference models to prune data based on their perplexities. This process has been shown to improve downstream performance and reduce pretraining steps by up to 1.45x, enhancing the efficiency of training and model optimization.
Q: What is the Video-MME Benchmark introduced by Akhaliq?
A: The Video-MME Benchmark is the first comprehensive evaluation benchmark for multi-modal Large Language Models (LLMs) on video analysis, covering 6 visual domains, video lengths, multi-modal inputs, and manual annotations. This benchmark showcased Gemini 1.5 Pro significantly outperforming open-source models in various tasks.
Q: What are the criticisms and opinions shared by Yann LeCun in the AI Ethics and Societal Impact section?
A: Yann LeCun criticized AI doomerism and singularitarianism as 'eschatological cults', arguing that they drive insane beliefs and make people feel powerless rather than finding solutions. He also condemned attacks on Dr. Fauci by Republican Congress members as 'disgraceful and dangerous', highlighting the importance of public health trust and the risks of attacks on science.
Q: What are some AI applications and demos highlighted in the essai?
A: Some of the AI applications and demos showcased include the Dino Robotics Chef using object localization and 3D image processing, the SignLLM model for generating sign language videos in multiple languages, Perplexity Pages for converting research into articles, reports, and guides, and demonstrations of humanoid robots and custom AI video models like NOVA-1 by Higgsfield.
Q: What discussions took place in the Perplexity AI Discord channel?
A: The discussions in the Perplexity AI Discord channel revolved around new API users seeking model guidance, differences between small and large models, and inquiries about the possibility of a TTS (Text-to-Speech) API from Perplexity using services from 11Labs, showcasing the active engagement and curiosity within the community.
Q: What are some of the technical discussions and updates within the CUDA MODE channels?
A: In the CUDA MODE channels, there were discussions on integrating TorchAO quantization support, confusion clarification on 'hurn model', resolving dataset upload issues in FineWeb, and ongoing project roadmap discussions in the bitnet channel, highlighting the technical depth and collaboration within the community.
Q: What are some of the upcoming events and discussions in the AI community?
A: Upcoming events and discussions in the AI community include the PyTorch docathon focused on improving performance-oriented documentation, discussions on utilizing LLMs for generating technical documentation and legal document assistance, and proposals for using LLMs to aid in course forum responses, showcasing the diverse applications and discussions surrounding language models in various contexts.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!