[AINews] Is this... OpenQ*? • ButtondownTwitterTwitter
Chapters
Header and Email Content
AI Reddit Recap
AI Community Highlights and Collaborations
Interconnects (Nathan Lambert)
Discord Channel Summaries
Unsloth AI (Daniel Han) Update
Meta tackles large-scale AI training challenges, Interview with Esolang Academics, and more
LM Studio Models Discussion
HuggingFace Forum Highlights
HuggingFace and OpenAI Discussions
Integrating Huggingface's Chat-UI Project
Nous Research AI Community Updates
Modular Mojo Nightly Updates
Eleuther Discussion on LM-Thunderdome
LLM Finetuning Discussions
Interconnects (Nathan Lambert)
Models and Configuration Discussions
Header and Email Content
This section of the web page includes the header of the email, which features the AI News brand. The email content provides a recap of AI-related news and developments from various platforms such as Twitter, Reddit, and Discord. It highlights incremental releases and discussions around 'test-time' search, as well as a list of related research papers. Additionally, a Table of Contents for the email is provided for easy navigation.
AI Reddit Recap
Improved CLIP ViT-L/14 for Stable Diffusion:
- An improved CLIP ViT-L/14 model is available for download in /r/StableDiffusion, along with a Long-CLIP version, which can be used with any Stable Diffusion model.
Mixed Precision Training from Scratch:
- In /r/MachineLearning, a reimplementation of the original mixed precision training paper from Nvidia on a 2-layer MLP is presented, diving into CUDA land to showcase TensorCore activations.
Understanding LoRA:
- Also in /r/MachineLearning, a visual guide to understanding Low-Rank Approximation (LoRA) for efficient fine-tuning of large language models is shared. LoRA reduces the number of parameters involved in fine-tuning by 10,000x while still converging to the performance of a fully fine-tuned model.
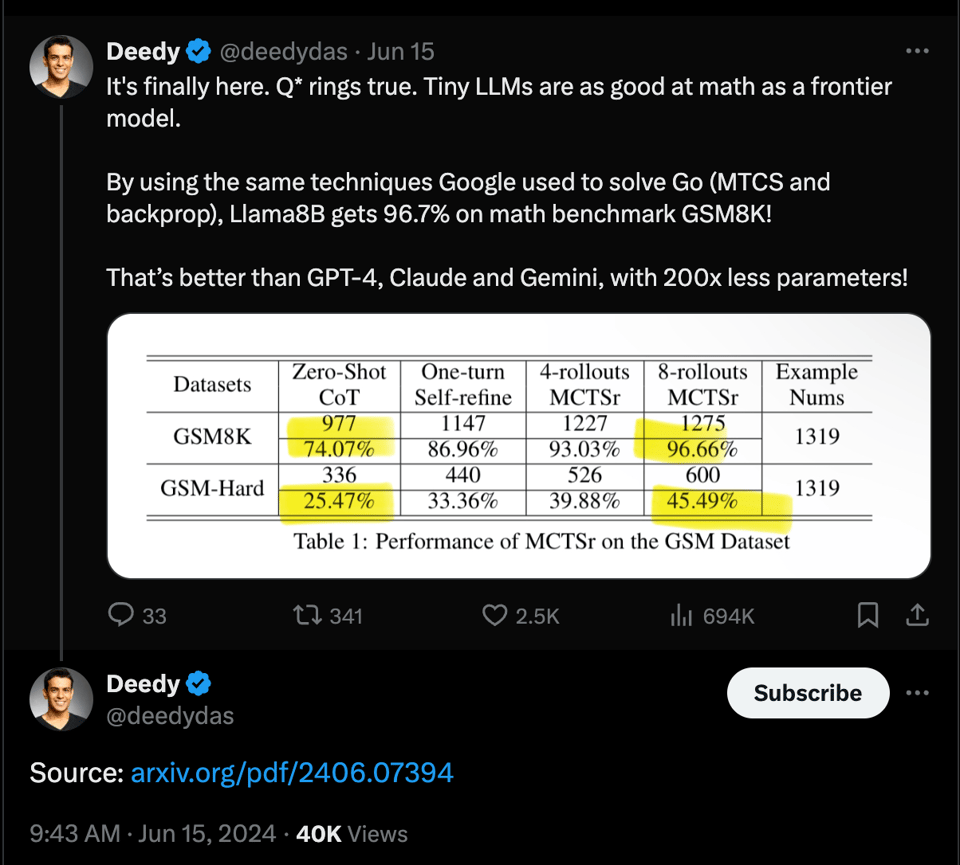
GPT-4 level Math Solutions with LLaMa-3 8B:
- A research paper explores accessing GPT-4 level Mathematical Olympiad solutions using Monte Carlo Tree Self-refine with the LLaMa-3 8B model.
Instruction Finetuning From Scratch:
- An implementation of instruction finetuning from scratch is provided.
AlphaMath Almost Zero:
- Research on AlphaMath Almost Zero introduces process supervision without process.
AI Community Highlights and Collaborations
The AI community is buzzing with collaborative projects and user engagement across various platforms like Lumalabs and Mojo Community Meeting. From AI integration in practical tools to lively discussions on music and AI-driven innovations, the AI enthusiasts are pushing the boundaries of creativity and practical application. Issues around licensing, technical discussions, seeking alternatives, and misinformation allegations also make rounds, showcasing the diverse range of topics discussed in the AI community.
Interconnects (Nathan Lambert)
Various updates and advancements in the AI industry were discussed, including Sakana AI joining the Unicorn Club, Runway's Gen-3 Alpha for video generation, DeepMind's video-to-audio breakthrough, Wayve's view synthesis model, and speculations about OpenAI's future governance. These discussions shed light on the rapid developments and transformations occurring in the AI landscape.
Discord Channel Summaries
Torchtune Discord
- Torchtune is focusing on optimizing single node training and exploring multi-node training configurations with tools like TorchX and slurm.
DiscoResearch Discord
- The Llama3 tokenizer has not been modified for the German model, leading to concerns about its efficiency. Members noted the large size difference between Llama2 and Llama3 tokenizers.
Datasette - LLM (@SimonW) Discord
- ChatGPT's role in the tech landscape as a job generator for data engineers was humorously discussed. A guide by Thoughtbot on Large Language Models (LLMs) was appreciated for its clarity. Turso's latest release integrating native vector search with SQLite was highlighted.
AI Stack Devs (Yoko Li) Discord
- Inquiries were made about the hospital AI project name within the AI Stack Devs community.
Mozilla AI Discord
- Discussion around the integration of Llama as a search companion in the Firefox browser was initiated.
Unsloth AI (Daniel Han) General
- Updates on Ollama support progress, template fine-tuning validation, and performance benchmarks were shared. Plans for multi-GPU support up to 8 GPUs were confirmed.
Unsloth AI (Daniel Han) Update
In this update provided by Unsloth AI (Daniel Han), several interesting discussions took place within the community. Members shared their musical preferences, experiences with Gemma 2 on AI Studio, and speculation about Gemini 2.0. Additionally, users sought and provided assistance on topics such as facing issues with Triton on Windows, data preparation tutorials for Unsloth fine-tuning, model training crashes, batch size and gradient accumulation, and errors with quantization_method in save.py. Furthermore, users discussed various topics related to CUDA, GPU technologies, and AI algorithms, highlighting the dynamic and collaborative nature of the community. Exciting developments such as privacy-preserving LLMs and upcoming NVIDIA GPUs were also mentioned. Overall, these conversations reflect the diverse interests and expertise of the community members, showcasing their shared passion for technology and innovation.
Meta tackles large-scale AI training challenges, Interview with Esolang Academics, and more
The section discusses various topics including Meta's challenges in training large language models, an interview with Esolang Academics, and sharing of emojis and messages in different Discord channels. The discussions cover the complexity of AI training, upcoming YouTube content, and interactions related to different technical issues and developments in the AI community. Links to related articles, videos, and GitHub discussions are also provided for further reading and reference.
LM Studio Models Discussion
LM Studio Models Discussion
- Qwen2 and the search mishap: A user struggled initially with Qwen2 instruct outputs and found a solution using the 'blank' preset, with advice to seek help within Discord.
- Roleplaying model recommendation: A member suggested Fimbulvetr-11B for roleplaying needs.
- Finding coding models amid confusion: Discussion on best coding models with a focus on Codestral and exploring a list of Large and Small Language Models.
- New 'Ultra-Quality' model releases: Highlighted releases of models like Psyonic-Cetacean-Ultra-Quality-20b-GGUF-imat-plus2 and testing results.
- Discussion on DeepSeek-Coder-V2: Excitement around DeepSeek-Coder-V2, focusing on VRAM requirements and flash attention settings for optimal performance.
HuggingFace Forum Highlights
In this section of the forum, various discussions and updates were shared by members on topics ranging from seeking a model for business use to experimentation recommendations. One user showcased their use of the GPT-4 API for a game screenshot project, while another member shared a critique of traditional RNN architectures in time series forecasting. Additionally, topics such as the impact of large language models on the labor market and the use of retrieval-augmented generation (RAG) to reduce AI hallucinations were also discussed. In another part of the forum, members engaged in discussions related to different strategies for image and text data, proposed operators like HyperZZW, and explored the concept of slow neural loss as a potential key element for future architectures. Overall, the forum provided a platform for members to share insights, projects, and questions related to AI and language models.
HuggingFace and OpenAI Discussions
HuggingFace ▷ #diffusion-discussions:
- Member seeks advice on developing a high-quality meme generator model and guidance on producing quality memes.
- Reports of rate limit exceeding errors, an Overflow error in Stable Diffusion XL, and a request for examples on using Diffusers with GCP's TPU.
OpenAI ▷ #ai-discussions:
- Discussions on ChatGPT compatibility with iOS 18, extracting transcripts from YouTube using tools like Otter.ai, open-source models outperforming GPT-4, connecting OpenAI models to databases, and capabilities of Luma's Dream Machine and Sora.
OpenAI ▷ #gpt-4-discussions:
- Members face issues with Custom GPTs privacy settings, propose funny ideas for GPT mods, encounter access issues with free-tier GPT interactions, inquire about specifying actions for Custom GPTs, and express frustrations over GPT usage limits.
OpenAI ▷ #prompt-engineering:
- Topics include challenges of 3D model creation, extracting information from GPT-4, generating detailed roadmaps with ChatGPT, handling ChatGPT's request refusals, and generating tables from XML data.
OpenAI ▷ #api-discussions:
- Discussions cover secrets to 3D model prompts, using separate samples for GPT-4, balancing shadows in 3D models, generating marketing roadmaps with ChatGPT, and addressing ChatGPT refusal quirks.
LAION ▷ #general:
- Conversations around SD3 model struggles, timestep weighting, open-source T2I models, ComfyUI and adaptive ODE solvers, and Fudan's open-source video generative model.
LAION ▷ #research:
- Topics include logical reasoning challenges, experiment tactics to address bias, reasoning sensitivity in models, symbolic AI hybrids for deductive reasoning, and JEPA for building a collective vision in email assistants.
OpenAccess AI Collective (axolotl) ▷ #general:
- Debate on large model usability, Qwen7B vs Llama3 8B performance comparisons, custom Llama3 template issues, GPU and optimization feedback for PyTorch, and shared projects and resources like CryptGPT and DanskGPT.
Integrating Huggingface's Chat-UI Project
- Provided links for setting up a chat UI similar to HuggingChat using Huggingface's chat-ui project.
- Users in the OpenAccess AI Collective discussed a bug halting Llama 3 development and the investigation into its source.
- Other discussions within the collective included configuration confusion, running axolotl on SLURM clusters, issues with QDora, and personality extraction using Axolotl.
- Members in the community showcase shared experiences with finetuning LLMs and exploring press release data extraction efficiency.
- Detailed discussions in the axolotl-help-bot channel included adjusting inference parameters, fine-tuning vision models, and handling different length contexts in models.
- Perplexity AI announcements featured a strategic partnership with SoftBank for offering Perplexity Pro free for a year.
- Multiple conversations in the Perplexity AI channels revolved around various searches, publication issues, and sharing of different topics.
- Interactions in the PPLX-API channel discussed struggles with custom GPT, closed-beta access for API, and project dependencies.
Nous Research AI Community Updates
The section provides updates on various interesting links within the Nous Research AI community. It includes diverse topics such as using living neurons to play video games, discussions on automated bias and indoctrination in AI, solving alignment problems in mASI, efficient LLM inference with vLLM, and stable diffusion subreddit protests. The section also covers updates on the world-sim AI experiences, discussions on Modular (Mojo) related topics like manual functions, typing mechanisms, community events, benchmark comparisons, and concerns about function coloring. Additionally, announcements and discussions about Modular via Twitter, blog releases, AI-related discussions about AGI solutions, and various technical discussions within the Mojo channel are highlighted.
Modular Mojo Nightly Updates
A series of updates for the nightly versions of the Modular Mojo compiler were released. The versions 2024.6.1505, 2024.6.1605, and 2024.6.1705 were announced, prompting users to update by executing 'modular update nightly/mojo'. Additionally, a request for documentation on built-in MLIR dialects was made, and users discussed a feature request for REPL improvements. The community shared insights and engaged in discussions to enhance the Mojo compiler's functionality.
Eleuther Discussion on LM-Thunderdome
A member pointed out the use of an outdated harness version by Hugging Face and observed significant differences in current results. There were inquiries about a platform for sharing evaluation results, independent validation for closed-source models, and resolving issues with multi-GPU evaluation in WANDB. Another member reported an issue with model config loading on Jarvis Labs, which was resolved by changing the version and token permissions. These discussions highlighted the importance of sharing evaluation results and resolving technical issues in model training and evaluation.
LLM Finetuning Discussions
LLM Finetuning Discussions
- Session Anticipation: A user humorously inquired about the probability of a new session.
- Memory Efficiency Project: Updates on a new project focusing on memory efficiency were shared, promising an upcoming interesting talk.
- OOM Errors Troubleshooting: Discussions on troubleshooting Out-Of-Memory errors with local LORA models and suggestions for quantization solutions.
- Documentation Gap: Requests for better documentation on finetuning, including training settings and proper loading techniques.
- Model Loading Guide: Insights on identifying the last trained model for effective inference.
- Adapting axolotl for Multi Chat Conversations: Inquiries about adapting axolotl for multi chat conversations and shared resources for conversation fine-tuning.
Links mentioned: Axolotl Dataset Formats, Axolotl - Config options, LLM-Finetuning script, Model Loading insights, Hamel’s course repo for sanity checks
Interconnects (Nathan Lambert)
The section discusses various topics related to Interconnects where members compliment the quality of merchandise, dissect ARC-AGI performance, explore neurosymbolic AI, mention MidJourney's new ventures, and ponder on conundrums at academic conferences. The section also includes links mentioned related to Apparate AI, a tweet from François Chollet, improving performance in ARC-AGI, and coding examples for drawing more samples in ARC AGI. This section provides insights into the ongoing discussions and developments within the Interconnects community.
Models and Configuration Discussions
- Worship Criticized: Users shared experiences with the Qwen2 model, criticizing it as overly censored. Alternative models like Dolphin Qwen 2 were recommended.
- Gemini Flash's Context Limit Debate: A discrepancy in token generation limits prompted questions, clarified by OR to match pricing models.
- Rate Limits and Model Configuration Questions: Users inquired about rate limits for models like GPT-4o and Opus, discussed maximizing model performance and configuration settings, emphasizing custom retry options and API call efficiency.
FAQ
Q: What is CLIP ViT-L/14 model?
A: CLIP ViT-L/14 is a model that combines the CLIP (Contrastive Language-Image Pre-training) framework with the Vision Transformer (ViT) architecture to enable visual reasoning and understanding within AI systems.
Q: What is mixed precision training in the context of AI?
A: Mixed precision training is a technique that leverages lower numerical precisions like FP16 (half-precision) and bfloat16 to accelerate training in deep learning models, especially benefiting hardware that supports such precisions like modern GPUs.
Q: What is LoRA in the context of machine learning?
A: LoRA stands for Low-Rank Approximation, a technique used to reduce the number of parameters involved in fine-tuning large language models significantly while maintaining performance levels similar to fully fine-tuned models.
Q: How does the Monte Carlo Tree Self-refine with the LLaMa-3 8B model work?
A: The Monte Carlo Tree Self-refine technique with the LLaMa-3 8B model enables accessing GPT-4 level Mathematical Olympiad solutions by iteratively refining the tree search process to provide accurate and high-quality solutions.
Q: What is meant by instruction fine-tuning from scratch?
A: Instruction fine-tuning from scratch involves starting the fine-tuning process of a model from the beginning without leveraging pre-existing weights or parameters, allowing for customizing the model to specific tasks or datasets.
Q: What is the focus of Torchtune Discord?
A: Torchtune Discord focuses on optimizing single node training and exploring different configurations for multi-node training using tools like TorchX and slurm to enhance the efficiency and performance of deep learning models.
Q: How is the AI community engaging in practical applications and discussions?
A: The AI community is actively involved in collaborative projects and engaging discussions across platforms like Lumalabs and Mojo Community Meeting, exploring AI integration in practical tools, sharing insights on AI-driven innovations, and discussing topics like music and licensing issues.
Q: What are some of the recent updates in the AI industry?
A: Recent updates in the AI industry include Sakana AI joining the Unicorn Club, Runway releasing Gen-3 Alpha for video generation, DeepMind achieving a breakthrough in video-to-audio translation, Wayve developing a view synthesis model, and speculations about the future governance of OpenAI.
Q: What are some common topics discussed in the AI community forums?
A: Common topics discussed in AI community forums include technical discussions, licensing issues, seeking alternatives, misinformation allegations, advancements in AI technology, collaborative projects, user engagement, and diverse discussions around AI algorithms, privacy, and upcoming developments.
Q: What is the significance of LLM Studio Models Discussion?
A: LLM Studio Models Discussion provides insights into the discussions related to different language models, their applications, experimental recommendations, challenges in training and evaluating models, and the community members' shared experiences and projects in the AI field.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!