[AINews] FSDP+QLoRA: the Answer to 70b-scale AI for desktop class GPUs • ButtondownTwitterTwitter
Chapters
FSDP+QLoRA: the Answer to 70b-scale AI for desktop class GPUs
High-Level Discord Summaries
DiscoResearch Discord
Discussing Model Performance and New Models in NousResearch AI Discord
Nous Research AI
LM Studio ▷ #open-interpreter (87 messages🔥🔥)
Eleuther Discussions
Discussions on OpenAI API
HuggingFace Diffusion Discussions
OpenRouter and Nitro Models Discussed
LangChain AI Chat Discussions
Find AI News Elsewhere
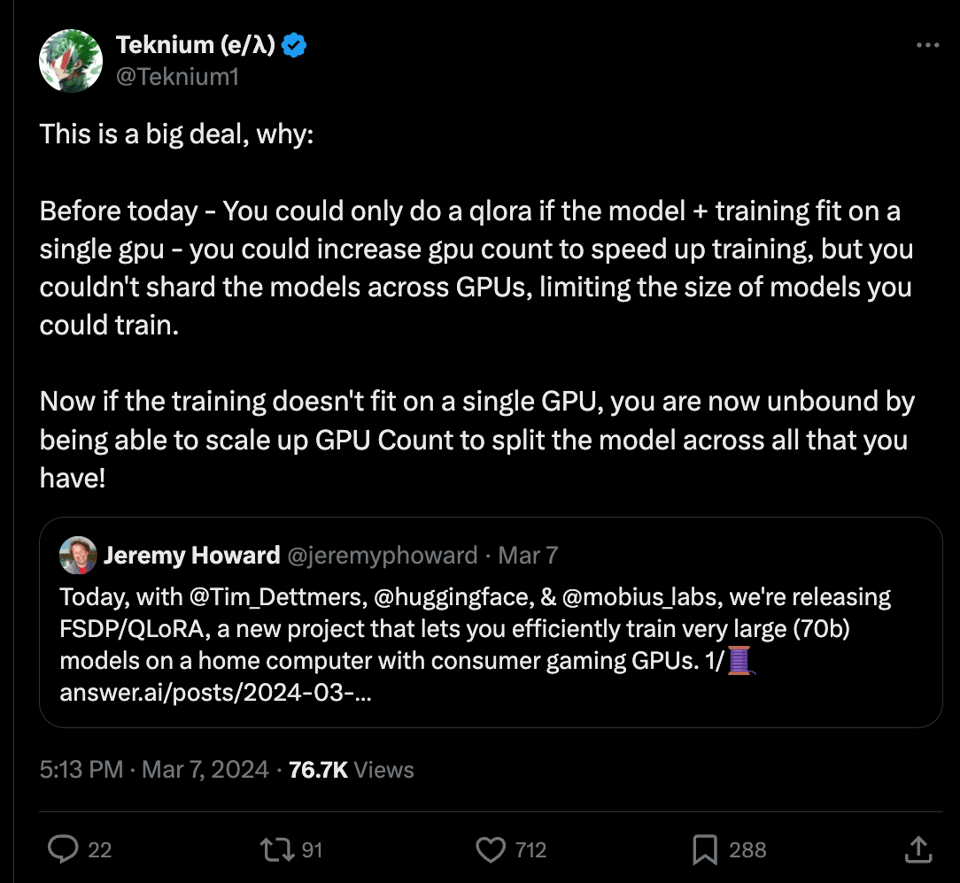
FSDP+QLoRA: the Answer to 70b-scale AI for desktop class GPUs
This section discusses a new tool introduced by Jeremy Howard et al that addresses the memory constraints of training large language models on desktop-class GPUs. The tool combines FSDP (Fully Sharded Data Parallel) with QLoRA to enable efficient training of 70b models on consumer gaming GPUs. By reducing the model size using QLoRA and distributing it across multiple GPUs with FSDP, it becomes possible to train models on more affordable hardware. The section also delves into the limitations of QLoRA, the benefits of using FSDP, and the integration of HQQ and other techniques to make the approach work effectively. Overall, the solution provides a way to overcome memory limitations and train large models on consumer-grade GPUs at a fraction of the cost of data center GPUs.
High-Level Discord Summaries
This section provides summaries from various Discord channels about AI-related discussions and developments. These summaries include topics such as meme generation using Mistral LLM and Giphy API, GaLore optimizer discussions, the launch of Doodle Wars multiplayer game, advancements in LM Studio software, AMD's focus on AI hardware optimization, Claude 3's diverse applications, and the challenges and solutions shared in different Discord communities. The content ranges from hardware recommendations for efficient AI development to updates on AI model performance comparisons and integration challenges in various Discord channels.
DiscoResearch Discord
In Search of a Sauerkraut-Flavored AI:
- There is a gap in German-fineturned models, with Nous Hermes Mixtral not catering to German language prompts, in comparison to sauerkraut oder discolm mixtrals.
DNA's New Best Friend:
- User @rasdani introduced the Evo architecture—Striped Hyena by TogetherAI, specialized for DNA sequencing. Information about its biology application can be found in their blog post, developed with the Arc Institute.
Discussing Model Performance and New Models in NousResearch AI Discord
In the NousResearch AI Discord channel, members engage in various discussions related to AI models and advancements within the field. Users share insights on swapping ChatGPT Plus for Claude Pro, bugs and fixes in Gemma AI, and the capabilities of the Llama 7B LLM. There are talks about the implications of multiple AI models potentially matching or surpassing GPT models and the scrutiny of Microsoft's partnership with Mistral AI by the EU. Overall, the community showcases a keen interest in the latest developments and challenges within the AI landscape.
Nous Research AI
Seeking Free GPT-4 Access:
- @micron588 inquired about accessing GPT-4 for free, with @teknium referencing Corcel.io as a platform providing free ChatGPT-4 access.
Misunderstood Model Name:
- @micron588 expressed skepticism about Corcel.io as GPT-4, clarified by @teknium.
Nous-Hermes Model Context Length Query:
- @nickcbrown asked about reduced context length in Nous-Hermes models, discussed by @night_w0lf.
Discussion on LLM Pretraining and Finetuning:
- Debate on LLM pretraining and fine-tuning nuances, LoRA, DoRA, VeRA, and GaLore by @teknium and @carsonpoole.
The Cost of Pretraining and Model Optimization Techniques:
- @umarigan highlighted resource-intensive pretraining, FSDP and QLoRA advancements by @eas2535, and skepticism from @teknium.
LM Studio ▷ #open-interpreter (87 messages🔥🔥)
Confusion Over Interpreter Options:
- User @nxonxi clarified the '-s' option as '--system_message' in the documentation.
Seeking Python Script Help:
- @nxonxi sought help setting the default system message in a Python script.
Troubleshooting Profile Issues:
- @nxonxi faced challenges implementing changes in intent profiles.
Exploring Different Language Models:
- Discussion on models like deepseek coder 6 and openchat/mistral.
Exchanging Model Insights and Recommendations:
- @1sbefore shared insights on GGUFs for HanNayeoniee/LHK_DPO_v1 and model limitations beyond 4000 tokens.
Eleuther Discussions
messages
- New Benchmarks for Korean Language Models: @gson_arlo announced the creation of two new Korean language evaluation datasets, Hae-Rae Bench and K-MMLU, designed to test language models' abilities to understand Korean-specific knowledge.
- Call for Multilingual Model Evaluation: @gson_arlo invited community members to design benchmarks for diverse languages and cultures to evaluate multilingual models.
General
- TensorRT Code Integration Pending Approval: @abhishekvijeev is integrating TensorRT code requiring approval due to company resources.
- Context Length in Training LLMs Discussed: @sentialx and @thooton_ discussed training large language models with varying context lengths.
- EEVE-Korean-v1.0 Introduced: @seungduk shared an arXiv report on adding more tokens to LLMs while maintaining performance.
- Open Invitation for ML/AI Research Collaboration: @andrew_f0874 offered collaboration in ML/AI research.
- Simple AI Discussions and Questions: @shida3916 sought a forum for everyday AI uses and simple questions.
Research
- GaLore's Memory Efficiency Draws Attention: Users discussed GaLore's potential and skepticism about its practical implementation.
- Anticipation for GaLore Replication: Users showed interest in seeing replication of GaLore results.
- Exploring GaLore's Codebase: Users examined GaLore's code and discussed Python's capabilities.
- CAME Optimizer Piques Curiosity: Users mentioned the CAME optimizer and interest in understanding its performance.
- Instruction Tuning Dataset Discussions: Users discussed instruction tuning datasets.
lm-thunderdome
- Custom Output Format Implementation: @pminervini inquired about customizing output format in the harness.
- MCQA Evaluation Paper Discussion: @nish5989 shared their paper on MCQA evaluation.
- The Question of Language-Specific Evaluation: @seanbethard questioned language-specific evaluation criteria.
- Confidence Interval Clarification: @yamashi sought clarification on calculating a confidence interval.
- BOS Token Usage Variances: @jwngx asked about BOS token standards.
multimodal-general
- New Member Seeking AI Knowledge: @shida3916 expressed interest in discussing everyday AI applications.
gpt-neox-dev
- Exploring Environment Setup Options: Discussion on setting up environments for GPT-NeoX development.
- NGC Container Contemplations: Introducing an NVIDIA NGC PyTorch container.
- Dependency Management Discussions: Conversation on managing dependencies effectively.
- Flash Attention Update Conundrum: Concerns about Flash Attention version inconsistencies.
- ProtoBuf Dependency Mystery Solved: Discussion on the need for the ProtoBuf dependency.
ai-discussions
- Sonnet vs ChatGPT: Comparison of Sonnet and ChatGPT.
- Anticipating GPT-4: Community members looking forward to GPT-4 release.
- Prompt Optimization Debate: Discussion on effective prompting with GPT 3.5.
- Seeking AI for Flashcard Creation: Inquiry about AI tool for converting lecture PDFs into flashcards.
- Encountering GPT-4 Issues: Concerns raised about GPT-4 responses.
Discussions on OpenAI API
- Consumer Decision Making: Users are deliberating between using a React-based agent or refining GPT with training data. @eskcanta suggests initially testing the base model to save effort and resources.
- Dialogue Improvement and Custom Instructions: Discussions involve creating more organic dialogue and avoiding repetitive phrases. @openheroes mentions the 'Customize ChatGPT' feature for guiding the model to mimic specific text examples.
- Professional Headshot Generation with DALL-E: Interest in generating professional headshots using DALL-E is discussed. @enkai3526 shares a humorous gaming-related response.
HuggingFace Diffusion Discussions
- Seeking Guidance on SDXL-Lightning LoRA Merging: User happy.j is looking for assistance on how to merge SDXL-Lightning LoRA with a standard SDXL model, expressing difficulty in finding resources beyond a HuggingFace discussion thread.
- Expert Recommendations for SDXL Variants: A member from the ByteDance organization recommends first training a regular SDXL model and then applying SDXL-Lightning LoRA for acceleration. For compatibility, training the SDXL with LoRA from the outset is preferred.
- Advanced Training Approaches for SDXL-Lightning LoRA: For quality improvements, ByteDance suggests merging SDXL-Lightning LoRA with the user's model and training further, cautioning that using MSE loss could dilute acceleration benefits. Employing an adversarial objective during training is considered the most advanced strategy, following the SDXL-Lightning paper's approach.
Links mentioned:
- ByteDance/SDXL-Lightning · finetune: no description found
OpenRouter and Nitro Models Discussed
Different models and features offered by OpenRouter, including the model selection process, pricing insights, and the introduction of Mistral 7b 0.2 Nitro model speed enhancements are highlighted. Users engage in discussions around Sonnet, Opus, and Sonnet affordability comparisons. The section also covers moderation layers, data retention practices, Anthropic's moderation strategies, and a debate on Nitro models, specifically Mixtral 8x7b instruct nitro. The discussion showcases users' interest and optimism towards new developments.
LangChain AI Chat Discussions
LangChain AI ▷ #general (21 messages🔥):
- LangChain JS Feature Query: @0x404blockchainnotfound inquired about feature parity between LangChain JS library and Python library without a direct answer provided.
- AGI Claims Discussed: @sales_god sought opinions on agent/AGI claims on Hacker News leading to a sidetracked discussion about LangChain tools.
- Finished Agent Event in Python: @cybersmiths reported a delay issue with the Finished agent event in Python without a solution provided.
- Handling PDF Loader Extractions: @yd4224 encountered formatting problems using langchain.document_loaders PyPDFLoader and received guidance on creating a custom loader.
- Push for JavaScript URL Loader: @mohitsakhiya077 expressed the need for document loading functionality in JavaScript similar to Python's UnstructuredURLLoader.
LangChain AI ▷ #langchain-templates (9 messages🔥):
- Redis Chat History Woes: @justanothergraphguy faced issues with chat history in Redis and structured output parsing using a pydantic model.
- Designing the Prompt and Model: System prompt for a 'User Profile Builder' to extract user info and build a profile.
- Technical Setup Unveiled: @justanothergraphguy shared Python code integrating langchain modules to create a chat chain.
- First Interaction Flawlessly Executed: Example showed correct extraction of user info.
- Subsequent Interaction Confusion: Follow-up interaction had memory issues with content display.
LangChain AI ▷ #share-your-work (2 messages):
- Visual AI in Spotlight: @vru.shank announced a workshop on MultiOn and Quizizz's use of vision models.
- Prompt Mixer Development: @tomatyss developing Prompt Mixer for AI prompts testing and iteration.
Links mentioned:
- No Title Found - no description found
- Multi-Modal LLMs in Prod - LLMs in Prod community workshop
- Prompt Mixer - Prompt IDE for crafting AI prompts
- Create a Custom Connector - Tutorial to create a custom connector
Find AI News Elsewhere
Check out AI news and updates on other platforms:<br>- Follow on Twitter<br>- Subscribe to the Newsletter<br>This content is brought to you by Buttondown, a platform to start and expand newsletters.
FAQ
Q: What is FSDP (Fully Sharded Data Parallel) and how does it address memory constraints in training large language models on consumer gaming GPUs?
A: FSDP is a tool introduced by Jeremy Howard et al that enables efficient training of large language models on consumer gaming GPUs by distributing the model across multiple GPUs, thus overcoming memory limitations.
Q: What is QLoRA and how does it contribute to training 70b models on more affordable hardware?
A: QLoRA is a tool that reduces the size of models, making them more affordable to train on consumer-grade GPUs when combined with FSDP for distribution across GPUs.
Q: What are some benefits of using FSDP in training large language models?
A: FSDP allows for the distribution of models across multiple GPUs, enabling training of large language models on more affordable hardware and overcoming memory constraints.
Q: How does the integration of HQQ and other techniques enhance the effectiveness of the approach discussed?
A: The integration of HQQ and other techniques enhances the approach by providing additional optimizations and strategies to make training large models on consumer-grade GPUs more efficient.
Q: What are some limitations of QLoRA mentioned in the essai?
A: The essai discusses limitations of QLoRA in the context of reducing model size and enabling training on consumer gaming GPUs for large language models.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!