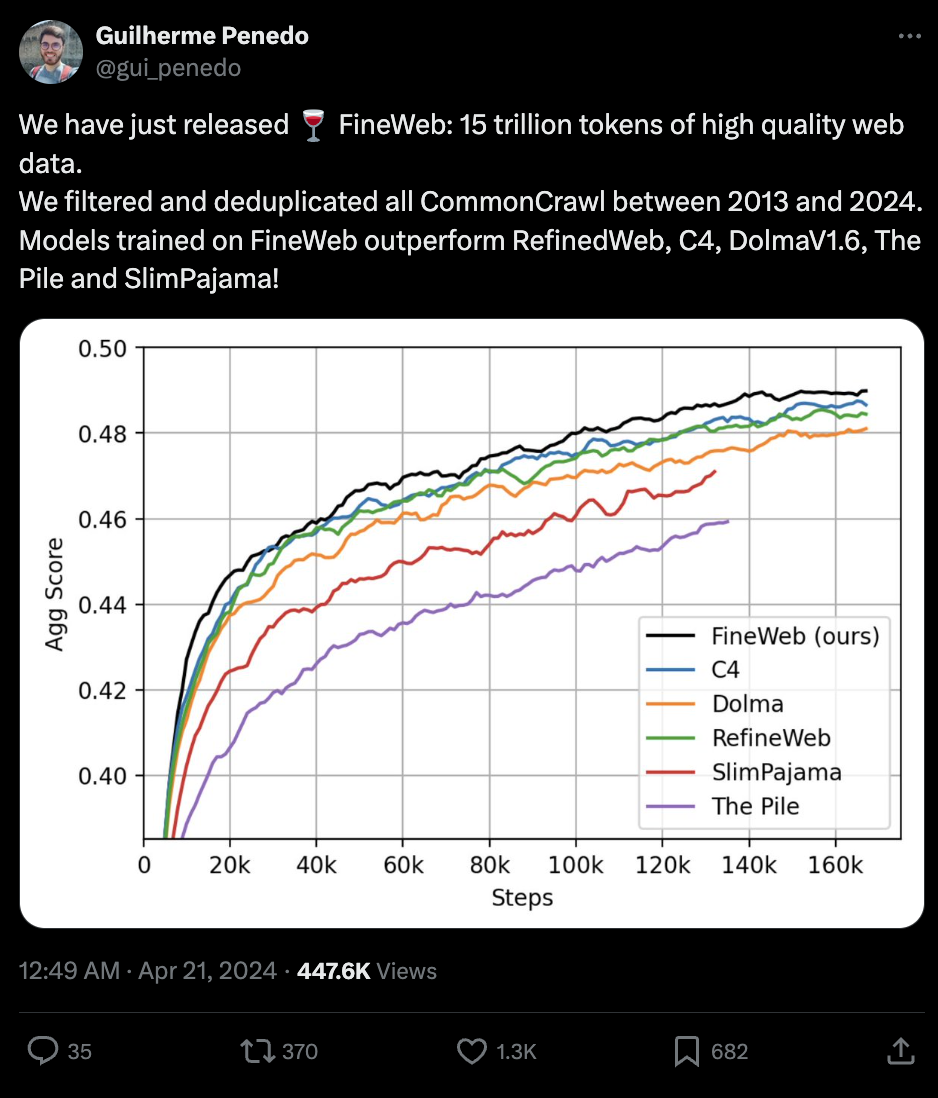
[AINews] FineWeb: 15T Tokens, 12 years of CommonCrawl (deduped and filtered, you're welcome) • ButtondownTwitterTwitter
Chapters
AI Reddit, Twitter, and Discord Recaps
Optimizing Transformer Models
DiscoResearch Discord
AI Models and Advances in Various Discord Channels
Unsloth AI Updates
Community Developments Around Perplexity AI
Discussion on Large Language Models and LLMs
Hardware Discussion in LM Studio
Issues and Solutions in LM Studio Settings
Triton Kernel Troubleshooting and Development
CUDA MODE and OpenAccess AI Collective Discussions
Exploring Task Vectors for Model Steering
Discussions on Modular (Mojo 🔥) Engine
Discussion on Recent Optimizations and Model Issues
Working with Open Source OCR Tools and Machine Learning Models
LLMaIn Action
AI Discussions and Collaborations
"LangChain AI" Section
Interconnects and Model Offerings
Chunking Content
AI Reddit, Twitter, and Discord Recaps
This section provides a detailed recap of the discussions happening in AI-related Reddit, Twitter, and Discord communities. From AI models and capabilities to benchmarks and leaderboards, from quantization and performance discussions to insights on censorship and safety, this recap covers a wide range of topics. It also touches upon the latest releases, performance evaluations, technical discussions, and tools/frameworks emerging in the AI space. The recap offers valuable insights into the ongoing conversations and developments surrounding AI technologies and their applications in various fields.
Optimizing Transformer Models
Techniques for optimizing transformer models were discussed in this section. This includes approximating attention mechanisms to compress token length during inference, extending context lengths with methods like Activation Beacon and TOVA, and dynamically allocating FLOPs. Collaborative efforts and community engagement were also highlighted, showcasing projects like minbpe-rs and an open-source matchmaking AI application using Cohere Command R+. Additionally, ethical considerations, legal implications, and discussions on collaborative efforts in the AI community were addressed.
DiscoResearch Discord
Stirring the Mixtral Pot: A discussion on Mixtral training highlighted the use of the 'router_aux_loss_coef' parameter, which can significantly influence training success. Boosting Babel for Czech: Efforts are underway to expand Czech language support by adding thousands of tokens, with a focus on language inclusivity. German Precision in AI Models: Concerns regarding German language proficiency in Llama3 and Mixtral models were discussed, noting grammar and tokenizer quirks. Memory Overhead Matters More Than Tokens: Reducing vocab tokens does not enhance inference speed; memory footprint is more impactful. Chatbots Lean Towards Efficiency: Exploring the integration of cost-effective chatbots into CRMs by grouping functions and employing different model types for tasks.
AI Models and Advances in Various Discord Channels
The section provides updates on AI models and advancements discussed across different Discord channels. From Mozilla AI Discord addressing llama3 instruct format compatibility issues to Interconnects Discord anticipating new model releases, the discussions cover a wide range of topics. Additionally, the section highlights performance improvements of llama 3 models, community engagement strategies, and challenges faced with services like Azure's OpenAI. The content also delves into Databricks' GPU and LLM support rollout, operational guides for fine-tuning LLMs, and the lowered hosting costs offered by a Github repository for LLM deployment. Finally, the datasette - LLM Discord channel explores practical applications of AI in blueprints analysis, preflight checks in architecture, and the enhanced support of llama 3 models on systems with limited RAM.
Unsloth AI Updates
Llama 3 Model Release and Resources
Unsloth AI released Llama 3 70B INSTRUCT 4bit, allowing faster fine-tuning of Mistral, Gemma, and Llama models with less memory usage. A Google Colab notebook for Llama-3 8B is available.
Tutorials on the Horizon
Unsloth AI plans to release explanatory tutorials and a notebook for finetuning instruct models.
Coders in Confession
Members share anecdotes about coding struggles, like creating functions without full understanding and seeking advice on displaying output stats.
PyTorch and CUDA Education Resource
Participants share resources for learning PyTorch and CUDA through the CUDA Mode YouTube channel and Edward Yang's PyTorch dev Twitch streams.
Efficiency Versus Performance in LLM Training
Discussions highlight the need to balance computing resource efficiency and performance levels when choosing models for tasks, focusing on keeping infrastructure costs low even with smaller models.
Community Developments Around Perplexity AI
- Perplexity AI Making Waves: Infosys co-founder Nandan Nilekani praised Perplexity AI, calling it a 'Swiss Army Knife' search engine following a meeting with co-founder Aravind Srinivasan.
- YouTube Insights on Perplexity AI's Rise: A YouTube video titled 'Inside The Buzzy AI StartUp Coming For Google's Lunch' showcases the journey of Perplexity AI and their encounter with Meta AI chief Yann LeCun.
- High-value Discussions Around Perplexity AI: Community members share various Perplexity AI search queries, addressing topics from HDMI usage to positive parenting and Apple news.
- Sharing the Perplexity AI Experience: Members engage with and share different Perplexity AI search queries, emphasizing the collaborative aspect of the community.
- Media Spotlight on Perplexity AI's Leadership: Another YouTube video features 'Perplexity CTO Denis Yarats on AI-powered search,' exploring the engine's user-focused capabilities and significant growth since its foundation.
Discussion on Large Language Models and LLMs
The section discusses various topics related to large language models (LLMs) and provides insights into areas like fine-tuning, model comparisons, and benchmark systems. Members explore the challenges of unified vs. specific RAG databases and seek recommendations for evaluating RAG systems. The conversation delves into research papers on RAG, focusing on improving retrieval-augmented generation and incorporating external data. There are also mentions of unique RAG approaches, such as superposition prompting and metadata utilization.
Hardware Discussion in LM Studio
In the hardware discussion section of LM Studio, users engage in various topics related to hardware configurations and performance optimization. Discussions include GPU compatibility with LM Studio, upgrading laptops for improved performance, configuring multiple GPUs, and troubleshooting configuration errors. Members share advice on managing power draw for additional GPUs, exploring external GPU enclosures for laptops, and addressing errors related to GPU detection. The community also references a Reddit GPU buying guide for building systems suitable for LM Studio.
Issues and Solutions in LM Studio Settings
In this section, users discussed various performance issues and solutions in LM Studio. The issues included models not being visible in the software due to a bug in version 0.2.20, as well as a conversation on NFS mounting strategies. Additionally, misconceptions about tokens in language models were clarified, and discussions arose regarding token counts and the selection of specific GPUs for model deployment. Users also shared experiences with AutoGen, AVX beta updates, and compatibility questions related to ROCm. Lastly, the introduction of Llama 3 in LM Studio ROCm Preview and its token generation speeds on different AMD GPUs were highlighted.
Triton Kernel Troubleshooting and Development
Interest was shown in implementing Triton or CUDA. NVLink inclusion in DGX boxes discussed. Unexpected grayscale transformation behavior in a Triton kernel resolved. Seeking Triton indexing capabilities and desire to implement binary search. Clarification on parameters in Triton functions. Use of cuda-mode's Triton utilities mentioned. Denseformer implementation in JAX discussed. Challenges with high memory usage and need for linear memory footprint in JAX. Custom backward pass for JAX recommended. Kernel optimizations in CUDA discussed including speed improvements, cuDNN integration, and exploring data parallelism. New dataset for training LLMs and the conversation on mixed precision in mainline code. NCCL examples and links to related discussions provided.
CUDA MODE and OpenAccess AI Collective Discussions
Discussions in the CUDA MODE channel included requests for presenting privileges, announcements of a new Moderator role, and coordination for event call preparation. In the OpenAccess AI Collective discussions, users reported issues with LLaMa-3 fine-tuning, debugged distributed training problems, explored custom dataset structures, and debated the efficiency of tokenizers. Additionally, discussions in the axolotl-dev channel included requests for computing resources to test updates, a feature request for a fused operation in PyTorch, and insights on VRAM consumption in large models. Furthermore, discussions in the general-help channel touched on fine-tuning challenges with Llama3, users seeking resources, FSDP compatibility with FFT, and quantization configurations for large models. Lastly, conversations in the runpod-help channel addressed delays in spinning up pods on Runpod, an upload limit workaround using huggingface_hub, methods for managing VRAM via the command line, and discrepancies in CPU memory reporting.
Exploring Task Vectors for Model Steering
A method called task vectors is proposed for steering the behavior of a pre-trained model, allowing modification through arithmetic operations like negation and addition. This could enable the addition of specialized knowledge to models like Llama3 without direct fine-tuning (as per arXiv:2212.04089).
Discussions on Modular (Mojo 🔥) Engine
Members of the Modular (Mojo 🔥) engine channel compared the performance between Python/Mojo and C++ implementations, noting that inference time in C++ is slightly faster due to the lack of Python runtime API calls. They dissected snippets of Python code for image processing, indicating heavy calls into the Python runtime leading to runtime overhead. Optimization discussions were also raised, highlighting the ongoing exploration of improving performance and efficiency in different language implementations.
Discussion on Recent Optimizations and Model Issues
- Max Optimization for NLP/LLM Inferences: While Max is optimized for NLP/LLM inferences, future optimizations for other types of models, including CNNs, are being explored.
- Input Tensor Naming Issue in ONNX Models: A solution using Python's
evaluate to set itemwas suggested to address an issue with an ONNX model input tensor named "input.1". - Solving Python API Tensor Name Issues: Unpacking (
**) was proposed as an approach to deal with tensor naming issues in ONNX models. - Pointer Pondering: Discussions revolved around various pointer types in the codebase, with efforts underway to refactor code.
- SIMD Alias Advocacy: The community discussed introducing aliases for
SIMD[T, N]and floats to streamline naming conventions. - Int Conversion Confusion: Suggestions were made to replace the removed
SIMD.to_int()function withint(SIMDType). - Vacation Notification: A member informed the community of their upcoming absence and provided alternative contacts.
- String Comparison Implementation Inquiry: A potential implementation for string comparisons in Python-style syntax was shared for community feedback.
Working with Open Source OCR Tools and Machine Learning Models
The section discusses the use of open-source OCR tools like Nougat for converting academic documents, such as math papers, from PDF to LaTeX. It also covers the gratitude expressed towards Mark Zuckerberg for providing open-source tools. Additionally, there are inquiries about architectural approaches for ML models, improvements in badminton shuttlecock tracking, and developing private knowledge bases. The HuggingFace NLP channel talks about fine-tuning challenges, new Rust port announcements, and BERTopic issues. In the diffusion-discussions section, topics include Lora training for inpainting, tool use in chatbots, and LLM comparisons. Lastly, the Latent Space channels mention discussions on LLMA-3 performance, latency improvements, and a new data set called FineWeb with 15 trillion tokens.
LLMaIn Action
The Latent Space discussion group on AI-in-action-club touched on various topics such as transitioning meetings from Discord to Zoom, sharing evaluation strategies for language models, discussing signal integrity issues during calls, and exploring evaluation methodologies for language models. In-depth conversations included strategies for model evaluation, links to additional resources, and discussions on AI model performance improvements. Furthermore, the LAION group explored Meta's approach in withholding the LLaMA-3 paper, debated on prompt engineering techniques, and delved into the legal risks of using Nightshade. The group also discussed AI model optimization, Blink benchmarks for multimodal language models, and the challenges of upscaling image models. Lastly, the LlamaIndex group shared insights on automating code writing with LlamaParse, crafting a local RAG app using Llama-3, introducing the DREAM framework for RAG experimentation, constructing a finance agent with LlamaIndex, and building memory-enhanced ColBERT retrieval agents.
AI Discussions and Collaborations
LlamaIndex:
- Discussions on confusion over attribute errors, using local vs. OpenAI in LlamaIndex, managing output verbosity, troubleshooting VectorStoreIndex query results, and handling file loading errors.
OpenInterpreter:
- Explorations with Infini Attention, AI raise tracking, AI distribution visualization, integration of FireCrawl with LlamaIndex, and updates on Knowledge Graph SDK.
Cohere:
- Cohere community discusses MySQL connector integration, limits of commercial use for Command R, AI startup founder seeking talent, job hunt strategies post Cohere internship rejection, and an ML-Maths talk alert by Dr. Matthew Bernstein on VAEs in single-cell genomics.
Project Sharing:
- Open source code release for a matchmaking AI application leveraging Cohere's Command R+ with integrations like stanfordnlp DSPy and weaviate_io Vector store.
"LangChain AI" Section
Breakdown of Messages:
- Seeking FstAPI Route Code: A member seeks FstAPI route code related to pirate-speak but faces difficulty locating it.
Summary of Links Mentioned:
- ChatAnthropic | LangChain.js - v0.1.34: Provides no description.
- Learn How LLAMA 3 Works Now: The Complete Beginner’s Guide: Details LLAMA 3 model concepts.
- Quickstart | 🦜️🔗 Langchain: Guides on creating Chains and Agents in Langchain.
- ChatVertexAI | 🦜️🔗 Langchain and ChatVertexAI | 🦜️🔗 Langchain support Google Vertex AI chat models.
- Issues · langchain-ai/langchain?utm_source=ainews&utm_medium=email&utm_campaign=ainews-fineweb-15t-tokens-of-commoncrawl): Tracks context-aware reasoning applications development on GitHub.
Interconnects and Model Offerings
Interconnects (Nathan Lambert) ▷ #news
-
Anticipation for new model sizes with a release plan for 100M, 500M, 1B, and 3B models trained on around 5 trillion tokens to replace the current pythia suite.
-
Aligning with AI community desires, possibly developing AI models in line with Karpathy's preferences.
-
Sparse Latent Models and small vision models are considered compelling projects to work on.
-
Excitement for the success of MiniCPM, highlighting the interest in creating compact yet powerful models.
-
LLAMA 3 8B has set an impressive standard, with upcoming Phi-3 mini 4b, small 7b, and medium 14b models poised to exceed benchmarks.
-
Importance of proper model training processes highlighted, emphasizing that shortcuts lead to subpar results.
Chunking Content
Chunking content involves breaking down information into smaller, manageable sections to enhance cognitive load and facilitate better understanding. This technique is commonly used in web design to improve user experience and retention. By organizing content into digestible chunks, users can process information more effectively, leading to higher engagement and satisfaction.
FAQ
Q: What is the focus of the discussions happening in AI-related Reddit, Twitter, and Discord communities?
A: The discussions focus on AI models, capabilities, benchmarks, leaderboards, quantization, performance discussions, insights on censorship and safety, latest releases, performance evaluations, technical discussions, and tools/frameworks emerging in the AI space.
Q: What techniques were discussed for optimizing transformer models?
A: Techniques discussed include approximating attention mechanisms to compress token length during inference, extending context lengths with methods like Activation Beacon and TOVA, and dynamically allocating FLOPs.
Q: What are some of the updates on AI models and advancements discussed across different Discord channels?
A: Updates include discussions on llama3 model performance improvements, community engagement strategies, challenges with services like Azure's OpenAI, Databricks' GPU and LLM support rollout, operational guides for fine-tuning LLMs, and lowered hosting costs offered by a Github repository for LLM deployment.
Q: What was released by Unsloth AI in relation to Llama 3 models?
A: Unsloth AI released Llama 3 70B INSTRUCT 4bit, allowing faster fine-tuning of Mistral, Gemma, and Llama models with less memory usage. Additionally, a Google Colab notebook for Llama-3 8B is available.
Q: What are some of the common themes discussed in the topics related to large language models (LLMs)?
A: Common themes include fine-tuning challenges, model comparisons, benchmark systems, challenges of unified vs. specific RAG databases, research papers on RAG, unique RAG approaches like superposition prompting and metadata utilization.
Q: What was proposed to steer the behavior of pre-trained models like Llama3 without direct fine-tuning?
A: The proposal of using 'task vectors' was made to steer the behavior of pre-trained models like Llama3, allowing modifications through arithmetic operations like negation and addition.
Q: What are some of the discussions in the section focused on hardware configurations and performance optimization?
A: Discussions include GPU compatibility with LM Studio, upgrading laptops for improved performance, configuring multiple GPUs, troubleshooting configuration errors, managing power draw for additional GPUs, exploring external GPU enclosures for laptops, and addressing errors related to GPU detection.
Q: What are some of the challenges and solutions discussed in LM Studio regarding performance issues?
A: Challenges and solutions discussed include models not being visible in the software due to bugs, misconceptions about tokens in language models, discussions regarding token counts and selection of specific GPUs for model deployment, experiences with AutoGen, AVX beta updates, compatibility questions related to ROCm, and the introduction of Llama 3 in LM Studio ROCm Preview.
Q: What are some of the topics discussed in the CUDA MODE channel?
A: Topics include presenting privileges, announcements of a new Moderator role, coordination for event call preparation, discussions in the OpenAccess AI Collective, and discussions in channels like general-help addressing fine-tuning challenges, seeking resources, FSDP compatibility with FFT, and quantization configurations for large models.
Q: What was discussed about the use of open-source OCR tools in the section?
A: Discussions included the use of open-source OCR tools like Nougat for converting academic documents from PDF to LaTeX, inquiries about architectural approaches for ML models, improvements in badminton shuttlecock tracking, and developing private knowledge bases.
Q: What are some of the discussions in the section focused on AI model performance improvements in the LAION group?
A: Discussions include Meta's approach in withholding the LLaMA-3 paper, prompt engineering techniques, legal risks of using Nightshade, AI model optimization, Blink benchmarks for multimodal language models, and challenges of upscaling image models.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!