[AINews] Cerebras Inference: Faster, Better, AND Cheaper • ButtondownTwitterTwitter
Chapters
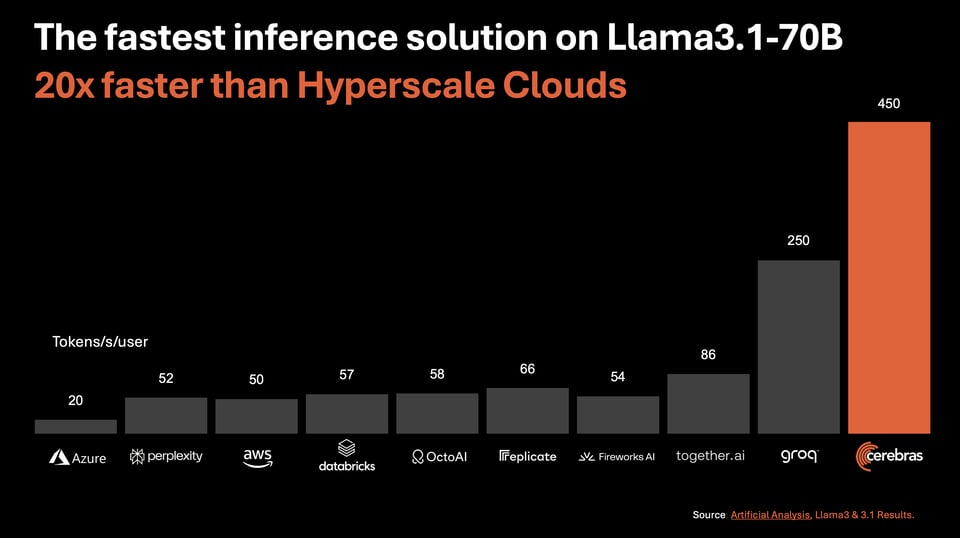
Cerebras Inference: Faster, Better, AND Cheaper
Advancements in Efficient AI Models and Benchmarking
Challenges and Comparisons in Various Models
Capabilities and Applications of Various AI Tools
Unsloth AI (Daniel Han) Community Collaboration
Perplexity AI General
LlamaIndex Overview
Interconnects - Google's Three New Gemini Models
Neural Network Development Updates
Llama 3.1 Benchmarking and Custom API for Llama 3.1
Cerebras Inference: Faster, Better, AND Cheaper
The section discusses the latest developments in AI, particularly focusing on the Cerebras Inference service. It compares the performance and pricing of different AI models and providers. Notable mentions include Gemini 1.5 models from Google, open-source models like CogVideoX-5B and Rene 1.3B, and discussions on distributed training and AI ethics. The section also covers AI applications, infrastructure, and insights shared on AI Twitter Recap. Additionally, the AI Reddit Recap includes highlights from /r/LocalLlama about open-source text-to-video AI models.
Advancements in Efficient AI Models and Benchmarking
The Gemini 1.5 Flash 8B model by Google, with 8 billion parameters, shows state-of-the-art performance and efficiency, outperforming larger models like Llama 2 70B. Google's use of standard transformers for Gemini sparked discussions about model performance and potential advancements. Other topics include OpenAI's upcoming 'Strawberry' AI, Google's Gemini 1.5 updates, and advancements in AI image generation and manipulation with models like Flux AI. Additionally, scientific breakthroughs like the discovery of DNA damage repair protein and discussions on AI ethics and societal impact are highlighted.
Challenges and Comparisons in Various Models
Model Merging: A member proposed merging the differences between UltraChat and Mistral into Mistral-Yarn as a potential strategy, despite skepticism from others.### Hermes 3 and Llama 3.1 Comparison: A comparison highlighted Hermes 3's competitive performance over Llama 3.1, with benchmark links provided.### Finetuning with Synthetic Data: Discussion on using synthetic data in finetuning models, focusing on Hermes 3 and 'strawberry models.'### OpenRouter Updates: OpenRouter API degradation, Llama 3.1 405B BF16 endpoint, Hyperbolic's BF16 Llama 3.1 405B Base, LMSys leaderboard relevance questioned, and OpenRouter DeepSeek caching in progress.### Eleuther Discussions: Free Llama 3.1 405B API, TRL.X status inquiry, model training data sources, reversing Monte Carlo tree search, and computer vision project feedback request.### LlamaIndex Queries: Supported OpenAI models, library updates, Pydantic v2 issue, GraphRAG authentication error solution, and building NL to SQL chatbot with LlamaIndex tools.### Torchtune Considerations: QLoRA & FSDP1 compatibility, torch.compile vs. Liger kernels, model-wide vs. per-layer compilation performance, impact of activation checkpointing, and balancing speed with compilation granularity.### OpenAI Contemplations: GPT-4 challenges, Mini model vs. GPT-4 comparison, SearchGPT vs. Perplexity strengths, AI sentience debate, and concerns on Orion model access.### Interconnects Updates: Google's new Gemini models, API usability discussions, SnailBot for link notifications, Open Source Data Availability predictions, and compiler nuances in Mojo Discord.### Latent Space Discoveries: Google's Gemini models, Anthropic's coding powerhouse, Artifacts mobile app launch, Cartesia's Sonic AI, and Cerebras' fast inference solution.### OpenInterpreter Developments: New instruction format, Daily Bots launch, Bland's AI phone agent, Jupyter Book metadata guide, and ongoing OpenInterpreter development.### OpenAccess AI Collective Insights: Axlotl on Apple Silicon, IBM's Power Scheduler, QLora FSDP parameters debate, and token behavior impact on model training.### DSPy Achievements: Success at MEDIQA challenge, potential 'ImageNet moment' at NeurIPS HackerCup, and increased adoption due to notable wins.
Capabilities and Applications of Various AI Tools
DSPy is not only effective for NLP but also for other domains like code generation, as demonstrated in a recent talk covering its use in the NeurIPS HackerCup challenge. For those interested in DSPy, a recent talk by @kristahopsalong on Weights & Biases provides a great starting point for exploring DSPy for coding, including its optimizers and a hands-on demo using the 2023 HackerCup dataset. Additionally, there was a user inquiry about changing the OpenAI base URL and model to a different LLM like OpenRouter API, with attempts to modify parameters in the code snippets.
Unsloth AI (Daniel Han) Community Collaboration
mrdragonfox made a statement in the Unsloth AI community collaboration channel. The conversation seems to revolve around unusual behavior observed by the user.
Perplexity AI General
Perplexity AI General
<ul> <li><strong>DisTrO's efficiency limitations</strong>: A discussion on utilizing DisTrO for training large LLMs on multiple devices, mentioning SWARM as a potentially better solution for specific scenarios.</li> <li><strong>DPO Training with AI-predicted Responses</strong>: Queries regarding using AI-predicted user responses for DPO training and its impact on enhancing theory of mind.</li> <li><strong>Model Merging Tactics</strong>: Suggestions for merging tactics between different models, including a specific approach with UltraChat and Mistral-Yarn.</li> <li><strong>Hermes 3 Outperforms Llama 3.1</strong>: A comparison between Hermes 3 and Llama 3.1 models, highlighting the former's competitiveness and possible superiority in various capabilities.</li> <li><strong>Concerns about "Llama 3.1 Storm" Model</strong>: Concerns raised about the creation of a new Llama 3.1 fine-tune named "Storm", suspected to have been derived partially from Hermes's system prompt.</li> </ul> <div class="linksMentioned"> <strong>Links mentioned</strong>: <ul> <li><a href="https://x.com/neurallambda/status/1828214178567647584?s=46&utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Tweet from neurallambda (open agi) (@neurallambda)</a>: Progress report on "Homoiconic AI" detailing innovative learning methodologies.</li> <li><a href="https://arxiv.org/abs/2408.11029?utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Scaling Law with Learning Rate Annealing</a>: Research discussing scaling laws in neural language models based on learning rate annealing.</li> <li><a href="https://n3rdware.com/accessories/single-slot-rtx-2000-ada-cooler?utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Nvidia RTX 2000 Ada Single Slot Cooler | n3rdware</a>: Product information on a single slot cooler for Nvidia RTX 2000 cards.</li> <li><a href="https://huggingface.co/akjindal53244/Llama-3.1-Storm-8B?utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">akjindal53244/Llama-3.1-Storm-8B · Hugging Face</a>: Repository for the Llama 3.1 Storm 8B model on Hugging Face.</li> <li><a href="https://x.com/reneil1337/status/1828827624900272628?utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Tweet from reneil.eth 🕳🐇 (@reneil1337)</a>: Interaction showing appreciation for views on NatureVRM.</li> <li><a href="https://x.com/repligate/status/1828604853486014837?s=46&utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Tweet from j⧉nus (@repligate)</a>: Humorous portrayal of a model's behavior leading to interesting insights.</li> <li><a href="https://arxiv.org/abs/1906.02107?utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Latent Weights Do Not Exist: Rethinking Binarized Neural Network Optimization</a>: Study challenging the treatment of latent weights in binarized neural network optimization.</li> <li><a href="https://www.reddit.com/r/duckduckgo/comments/1f2vrku/ai_assist_should_be_uncensored_and_generate/?utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Reddit - Dive into anything</a>: Reddit thread addressing uncensored AI assist implementation.</li> <li><a href="https://tenor.com/view/shikanoko-by-murya-gif-9501555167387334429?utm_source=ainews&utm_medium=email&utm_campaign=ainews-cerebras-inference-faster-better-and">Shikanoko By Murya GIF - SHIKANOKO BY MURYA - Discover & Share GIFs</a>: GIF presentation for entertainment purposes.</li> </ul> </div>LlamaIndex Overview
The section provides information on various topics related to Llama 3.1 8B performance expectations, model size, tagging conversations with topics, and explaining RAG systems in a ChatGPT interface. It also includes details on a Flex-Attention visualization tool and a Tiny ASIC for 1-bit LLMs. Additionally, the section mentions Nous Research AI discussions on research papers and interesting links. Lastly, updates from OpenRouter announcements, Eleuther general and research discussions, and LlamaIndex blog and general channels are highlighted.
Interconnects - Google's Three New Gemini Models
Google announced the release of three experimental Gemini models: Gemini 1.5 Flash-8B, Gemini 1.5 Pro, and Gemini 1.5 Flash. These models offer improved capabilities for coding, complex prompts, and have been significantly enhanced. The API's usability was discussed with frustration over limitations, including the evaluation of the 8B model on RewardBench. Additionally, a user questioned the Q* hypothesis relevance and its link to Monte Carlo Tree Search, expressing skepticism about OpenAI's release strategy.
Neural Network Development Updates
DSPy's "ImageNet Moment": DSPy's "ImageNet" moment is attributed to @BoWang87 Lab's success at the MEDIQA challenge, where a DSPy-based solution won two Clinical NLP competitions with significant margins of 12.8% and 19.6%. This success led to a significant increase in DSPy's adoption, similar to how CNNs became popular after excelling on ImageNet.
NeurIPS HackerCup Challenge: DSPy's Next "ImageNet Moment"?: The NeurIPS 2024 HackerCup challenge is seen as a potential "ImageNet moment" for DSPy, similar to how convolutional neural networks gained prominence after excelling on ImageNet. The challenge provides an opportunity for DSPy to showcase its capabilities and potentially gain even greater adoption.
DSPy for Coding: Getting Started: For those interested in DSPy, @kristahopsalong recently gave a talk on Weights & Biases about getting started with DSPy for coding, covering its optimizers and a hands-on demo using the 2023 HackerCup dataset. The talk provides a great starting point for anyone interested in learning more about DSPy and its applications in coding.
DSPy Talk on Weights & Biases: The talk by @kristahopsalong on Weights & Biases covered the latest information on DSPy's optimizers and included a hands-on demo of code generation using DSPy. The talk is available on YouTube at https://www.youtube.com/watch?v=yhYeDGxnuGY.
DSPy for Code Generation: DSPy is being used for code generation, with a recent talk covering its use in the NeurIPS HackerCup challenge. This suggests that DSPy is not only effective for NLP but also for other domains like code generation.
Llama 3.1 Benchmarking and Custom API for Llama 3.1
- A member inquired about benchmarking Llama 3.1 using a custom API and inference pipeline.
- They seek guidance on getting started with benchmarking and optimizing their system.
- Another member explores solutions to integrate a custom model handler for function-calling features.
FAQ
Q: What are some notable AI models and providers discussed in the essay?
A: Notable AI models and providers discussed include Gemini 1.5 models from Google, open-source models like CogVideoX-5B and Rene 1.3B, Llama 3.1, Hermes 3, Mistral, and UltraChat.
Q: What is the significance of Google's Gemini 1.5 Flash 8B model?
A: Google's Gemini 1.5 Flash 8B model with 8 billion parameters showcases state-of-the-art performance and efficiency, outperforming larger models like Llama 2 70B.
Q: What is discussed about AI ethics in the essay?
A: The essay covers discussions on AI ethics and societal impact, highlighting the importance of ethical considerations in the development and deployment of AI technologies.
Q: What are some topics related to Model Merging discussed in the essay?
A: The essay discusses a proposed merging strategy between UltraChat and Mistral into Mistral-Yarn, despite skepticism from others, showcasing the intricacies of model merging in AI.
Q: What are some key points mentioned about DSPy in the essay?
A: DSPy is highlighted for its effectiveness in NLP and other domains like code generation. It was used in the NeurIPS HackerCup challenge, and a talk by @kristahopsalong on Weights & Biases provided insights on getting started with DSPy for coding.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!