[AINews] AlphaProof + AlphaGeometry2 reach 1 point short of IMO Gold • ButtondownTwitterTwitter
Chapters
AI Twitter Recap
Multilingual Capabilities
AI Community Discussion Highlights
Exploring LangChain AI
AI Stack Devs (Yoko Li) Discord
Comparing GPU Performance and Heat Management
AI Model Releases and Discussions
Exploring AI Research Topics in Nous Research Discord Community
Debates on SIMD Behavior and Library Enhancements
Stability.ai (Stable Diffusion) Announcement
Eleuther Research Insights
Game Launch, Difficulty Comparison, New Member Introduction, Business Model Discussion
Structured Data Extraction and LlamaExtract Launch
LlamaIndex & Chatbot Developments
Presentation and Implementation Details
AI Twitter Recap
The AI Twitter Recap section provides an overview of recent updates in the AI community shared on Twitter. Claude 3.5 Sonnet conducted the recaps. The highlights include the release of Meta's Llama 3.1 with a 405B parameter model and Mistral AI's Large 2 with 123B parameters, featuring 128k context windows. Mistral Large 2 excels in coding tasks like HumanEval and MultiPL-E, while Llama 3.1 405B demonstrates superior performance in math.
Multilingual Capabilities
Multilingual Capabilities:
- Mistral Large 2's strong performance on Multilingual MMLU significantly surpasses Llama 3.1 70B base.
Licensing and Availability:
- Llama 3.1's more permissive license allows training on outputs. Mistral Large 2 is available under a research license for non-commercial use.
Deployment Options:
- Llama 3.1 is accessible through Together API and Fireworks. Mistral Large 2 can be tested for free on Le Chat.
Open Source AI and Industry Impact:
- The rapid progress of open-source AI models now rivals closed-source alternatives in performance.
Computational Requirements:
- Running Llama 3.1 405B locally requires significant hardware like 8xH100 GPUs.
AI Development and Research:
- Llama 3.1 utilized a large amount of synthetic data in its training process.
- There is a need for standardized benchmarks and highlighted limitations in current evaluation methods.
- Ongoing work in few-shot prompting and structured extraction are being explored.
AI Community Discussion Highlights
This section delves into various discussions and challenges faced by the AI community, ranging from the importance of privacy rights and data privacy in AI models to specific model performance issues and advancements. Key points include discussions on Llama 3's fine-tuning challenges, the importance of batching for inference speed, and AI's impact on job security. Additionally, insights are shared on the LM Studio Discord updates, with a focus on Llama 3.1 and the Mistral Large model. The section also covers HuggingFace Discord topics such as the introduction of Dolphin 2.9.3 Mistral Nemo 12b model and optimizing GPU configurations for LLMs. Furthermore, discussions on advancements in AI models, legal actions against AI-powered tools, and the challenges faced by different AI platforms like Perplexity AI, OpenAI, and Eleuther are outlined. The community is engaged in technical discussions, model performance assessments, and exploration of new tools, showcasing the dynamic and evolving landscape of AI technologies.
Exploring LangChain AI
Users in the LangChain AI Discord channel expressed frustration with inconsistent performance of LangChain agents utilizing open-source models. This led to discussions on the challenges faced in utilizing multi agents and integrating ConversationSummary with database agents. Additionally, a useful YouTube video titled 'Fully local tool calling with Ollama' was highlighted, focusing on clarifying tool selection and setting up agents correctly for consistent functionality.
AI Stack Devs (Yoko Li) Discord
AI Stack Devs (Yoko Li) Discord
- Excitement for AI Raspberry Pi: A user expressed enthusiasm over the AI Raspberry Pi project, prompting curiosity about its specifics. The request for more details suggests potential interest in its capabilities and applications within low-cost AI deployment.
- Inquiry for More Details: A member requested further information, stating, this is cool, tell us more regarding the AI Raspberry Pi discussions. This indicates an active engagement in the community around innovative AI projects using Raspberry Pi, likely looking to explore technical intricacies.
Comparing GPU Performance and Heat Management
Comparing GPU Performance and Heat Management
- Users discussed the limitations of older GPUs like the P40 in terms of performance and heat management compared to newer cards such as the RTX 3090. One user achieved 3.75 tokens/s with 4 P40s, while others highlighted the efficiency of the M3 Max for inference tasks.
- Concerns were raised about high temperatures and cooling needs of the P40, with some users recommending custom cooling solutions to address heat issues. Successful implementation of custom cooling ducts was reported.
- Discussions highlighted the performance differences between the RTX 3090 and M3 Max for AI tasks, with some users suggesting a dual 3090 setup for faster inference despite higher power consumption.
- Apple Silicon's M3 Max was praised for its quiet operation and power efficiency during LLM inferences, providing an alternative to traditional GPUs.
- Users also raised concerns about combining RTX and P40 GPUs, with varying experiences in stability and performance reported, from successful operations to caution regarding integrating older hardware.
AI Model Releases and Discussions
The section details the release of new AI models and advancements in the field. It includes the launch of the Dolphin 2.9.3 Mistral Nemo model with improved features, AI achievements in solving Mathematical Olympiad problems, an overview of the K-Nearest Neighbors algorithm, and discussions on job security in the age of AI. Additionally, it covers the development of models like W2V2-BERT for Ukrainian, autocomplete and phrase inference models, and the utilization of quantized Diffusers models for memory optimization and reduction in Orig PixArt Sigma checkpoint size. Various discussions on community engagement, bounty programs, and the challenges and advancements in AI projects are highlighted in this section.
Exploring AI Research Topics in Nous Research Discord Community
The Nous Research AI channels in the Discord community are abuzz with discussions on various AI-related topics. In the Nous Research AI general channel, conversations revolve around updates on LLaMA models, GPU usage efficiency, precision techniques in model training, synthetic data generation benefits, and OpenAI's feature developments. Members tackle issues such as the performance of LLaMA models, GPU comparisons, quantization impacts, synthetic data efficacy, and OpenAI progress. The engagement reflects a deep interest in advancing AI capabilities and understanding the nuances of model training and application. Additionally, discussions in other channels touch on grounded refusals, image-to-text finetuning, consumer-grade model usage, and potential overlaps between game development and AI. These exchanges provide valuable insights into different facets of AI research and development in the Discord community.
Debates on SIMD Behavior and Library Enhancements
Debates on SIMD Behavior:
The community is discussing the handling of SIMD comparisons, focusing on maintaining both element-wise and total comparison results to suit various use cases like any() and all(). There is consensus on prioritizing SIMD performance over compatibility with lists for applications like hash tables and database indexing.
EqualityComparable Trait and Overloading:
Discussions involve introducing Eq implementations to SIMD types for polymorphic behavior without overwhelming the standard library with multiple traits. Suggestions include separate functions for boolean and SIMD logic to meet trait requirements effectively.
Performance Focus Over API Complexity:
Emphasis is placed on keeping SIMD efficient while avoiding compromises for list compatibility. Dedicated vector types when necessary are preferred over overloading existing features for compatibility.
Proposals for Improved SIMD Functionality:
Proposals for types like AnyCmpSIMD and AllCmpSIMD are introduced to clarify and control comparison behaviors for SIMD types. These aim to balance mathematical expectations and practical coding needs without cluttering the trait system.
Future Directions in SIMD and Traits:
Participants suggest iterative improvements and formal recognition for function traits like FnAny and FnAll as future directions. Custom types are expected to seamlessly integrate with SIMD operations, awaiting advancements in iterator extensions within the framework.
Stability.ai (Stable Diffusion) Announcement
Introducing Stable Video 4D for Multi-Angle Generation:
We are excited to announce Stable Video 4D, our first video-to-video generation model that transforms a single video into dynamic novel-view videos with eight different angles. This model enables users to tailor outputs by specifying camera angles, thus enhancing creativity in video production.
Rapid Frame Generation with Stable Video 4D:
Stable Video 4D generates 5 frames across 8 views in approximately 40 seconds, significantly improving efficiency in video processing. This innovative approach offers unprecedented versatility for users aiming to create high-quality videos quickly.
Future Applications in Various Fields:
Currently in research phase, Stable Video 4D aims to enhance applications in game development, video editing, and virtual reality. Ongoing improvements are expected, focusing on further enhancing the model's capabilities and applications.
Comprehensive Technical Report Released:
In conjunction with the announcement of Stable Video 4D, a comprehensive technical report detailing methodologies, challenges, and breakthroughs has been released. Users can access the report for in-depth insights into the model’s development here.
Availability on Hugging Face:
The Stable Video 4D model is now available on Hugging Face, providing users easy access to this cutting-edge technology. This open access aims to foster experimentation and further development in the community.
Eleuther Research Insights
Inference Costs for Models
Members discussed the proposal for free inference for models like Mistral and the efficiency of using single layers or MoE across clusters. Concerns were raised about the possible reduction in advantages of MoE due to ineffective batch inference usage.
Meta's Research Strategy Under Scrutiny
Discussion highlighted Meta's approach of utilizing external research and optimizing code rather than leveraging model structures. Questions were raised about Meta's operational tactics and the need to adopt more efficient methodologies.
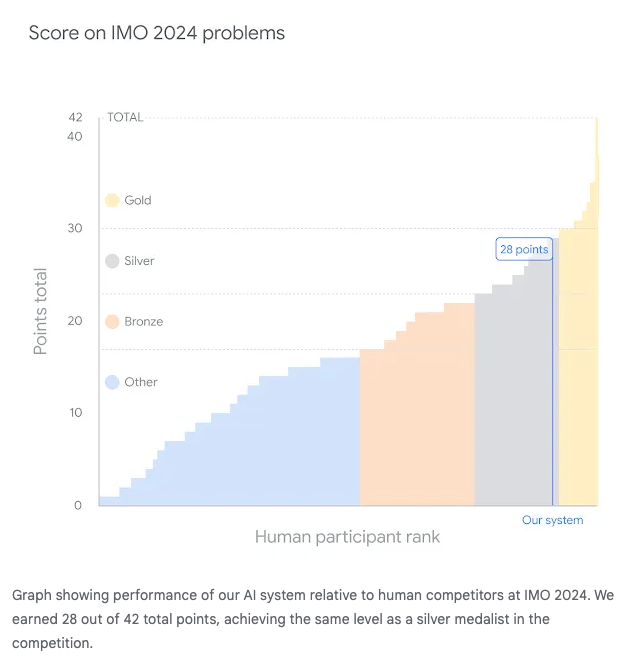
AlphaProof Success in Theorem Proving
The chat noted AlphaProof's success in solving 4 IMO problems, reaching a silver-medalist level. The breakthrough with AlphaProof emphasized its potential impact on mathematical methodologies with LLM integration.
xAI's Position Changes Amidst Competition
Conversations reflected skepticism around xAI's narrative and highlighted competition from DeepMind. Discussions focused on Musk's financial influence and the smart utilization of resources for xAI's long-term efficacy.
Protein Language Models Presentation
A member announced participation in ICML's ML4LMS Workshop, showcasing research on the use of protein language models for viral mimicry. The presentation hinted at emerging intersections between biology and AI within machine learning communities.
Game Launch, Difficulty Comparison, New Member Introduction, Business Model Discussion
Slider Launches as a Free Puzzle Game: Slider is a new free-to-play puzzle game worth checking out. The creator mentioned that the game is easier than Baba Is You, providing players with clear progress indicators.### Game Difficulty Comparison: A member compared the difficulty levels of Baba Is You and Slider, noting that Slider is easier to beat.### Welcome to a New Member!: A new member introduced themselves in the chat, expressing excitement about joining, contributing to a welcoming atmosphere in the community.### Discussion on Business Models in the Gaming Space: A discussion about the Adam Newman business model sparked speculation about attracting VC money with questionable practices. Although such scenarios were considered possible, no specific companies were suspected of engaging in these practices.
Structured Data Extraction and LlamaExtract Launch
A new release introduces structured extraction capabilities in LLM-powered ETL, RAG, and agent pipelines. Users can define a Pydantic object and attach it to their LLM for streamlined implementation.
LlamaIndex & Chatbot Developments
Today, an early preview of LlamaExtract, a managed service for structured data extraction from unstructured documents, was introduced. Users can infer a human-editable schema from documents for structured extraction based on user-defined criteria. Additionally, discussions on OpenAI Calls with MultiStepQueryEngine, RAG Chatbot Development, Updating Knowledge Graph Node Embeddings, Document Summary Index Errors, and Chunking and Triple Extraction Modifications were highlighted. Members clarified concerns about duplicate OpenAI calls, shared motivations to upgrade the RAG chatbot, debated managing outdated knowledge graph node embeddings, troubleshooted errors in Document Summary Index, and proposed an approach for integrating semantic chunking and triple extraction in the property graph code.
Presentation and Implementation Details
This section discusses various aspects related to creating a business-savvy presentation for OpenInterpreter, including seeking such a presentation, highlighting solutions to business challenges, showcasing success stories, and detailing implementation steps. Additionally, it covers topics related to Torchtune, such as generation recipes, single GPU fit issues, multi-GPU support status, and transitioning to distributed generation scripts. Furthermore, it delves into updates on Llama 3.1, memory management in fine-tuning, RFC for Cross Attention, and Snowflake optimizations. The section also explores advancements in Mistral Large 2, DFT Vision Transformer architecture, complex number parameters utilization, rotary position encoding impact, and streamlined architectural structure benefits. Lastly, it mentions developments in news categorization using DSPy, plans for a public GitHub repository, LangChain agent issues, multi-agent functionality, ConversationSummary integration, LangChain and Ollama video release, and updates on LangGraph persistence options.
FAQ
Q: What is the highlight of Meta's Llama 3.1 release?
A: Meta's Llama 3.1 release features a 405B parameter model that demonstrates superior performance in math tasks.
Q: What is the strength of Mistral Large 2 in coding tasks?
A: Mistral Large 2 excels in coding tasks like HumanEval and MultiPL-E, featuring 128k context windows.
Q: What are the licensing options for Llama 3.1 and Mistral Large 2?
A: Llama 3.1 has a more permissive license, allowing training on outputs, while Mistral Large 2 is available under a research license for non-commercial use.
Q: How can Llama 3.1 be accessed?
A: Llama 3.1 is accessible through Together API and Fireworks.
Q: Where can Mistral Large 2 be tested for free?
A: Mistral Large 2 can be tested for free on Le Chat.
Q: What are the computational requirements for running Llama 3.1 405B locally?
A: Running Llama 3.1 405B locally requires significant hardware like 8xH100 GPUs.
Q: What are the challenges faced by the LangChain AI Discord channel users?
A: Users in the LangChain AI Discord channel expressed frustration with inconsistent performance of LangChain agents utilizing open-source models and integrating ConversationSummary with database agents.
Q: What is Stable Video 4D and its primary feature?
A: Stable Video 4D is a video-to-video generation model that transforms a single video into dynamic novel-view videos with eight different angles.
Q: How fast can Stable Video 4D generate frames across different views?
A: Stable Video 4D can generate 5 frames across 8 views in approximately 40 seconds, significantly improving efficiency in video processing.
Q: Where is the Stable Video 4D model available?
A: The Stable Video 4D model is available on Hugging Face for easy access.
Q: What were some of the discussions around GPU performance and heat management?
A: Users discussed limitations of older GPUs like the P40 compared to newer cards like the RTX 3090, highlighting efficiency and cooling needs, as well as the performance differences between different GPUs for AI tasks.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!