[AINews] a quiet weekend • ButtondownTwitterTwitter
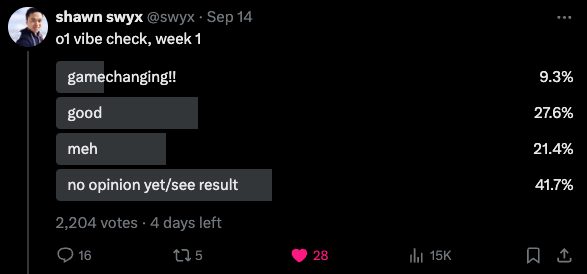
Chapters
AI Twitter Recap
AI Reddit Recap
AI Community Discussions
Unit Testing Importance and RAG Implementation
Challenges Faced in Utilizing Aider
Issues and Optimizations in AI Model Training
Challenges in Fine-tuning Models
Model Evaluations and Performance Insights
Challenges and Solutions in CUDA Development
LM Studio and Hardware Discussions
OpenAI and LLM Discussion
Cohere API Discussions
Eleuther Scaling Laws
Inquiries and Discussions on Various AI Topics
Issues with Function Calling
AI Twitter Recap
This section provides a recap of AI-related updates and developments from Twitter. It covers AI model developments like OpenAI's o1 Model and Google DeepMind's latest advancements. It also discusses industry updates from companies like Adobe and Tencent, as well as the release of research papers related to AI. Furthermore, the section includes insights on AI capabilities, benchmarks, and industry perspectives from prominent figures in the field.
AI Reddit Recap
Theme 1: Llama 3.1 405B: Open-Source Rival to GPT-4
-
Llama 405B demonstrated running locally on Apple Silicon hardware, achieving 2.5 tokens/sec speed.
-
Performance was enhanced by adding a Linux system with a 3090 GPU to the cluster.
-
Project utilizes 4-bit quantization and developers explore integration of Nvidia 3090 using tinygrad.
-
Users can try the setup using the Exo GitHub repository.
-
I ran o1-preview through a small-scale benchmark, achieving nearly identical scores to Llama 3.1 405B.
-
Benchmark results suggest o1-preview might be a fine-tuned version of Llama 3.1 405B, potentially matching GPT-4's capabilities.
Theme 2: O1 Model's Advanced Reasoning Capabilities
- Benjamin Klieger developed g1, a model inspired by O1 and powered by Llama-3.1 on Groq's hardware.
- Users debated the effectiveness of using prompts alone for replicating O1's performance.
- A potential method to reveal O1's thinking steps was discussed but received pushback from OpenAI.
Theme 3: Comparing Online LLM Providers and Services
- Discussion on various Large Language Model providers like OpenRouter and preferred combinations of providers.
- Google Gemini and CoHere popular for their free plans.
- Local solutions like Ollama and open-source alternatives are favored by some users to avoid subscription fees.
AI Community Discussions
Discussions in various AI community Discord channels highlight a range of topics and concerns. From advocating for fair recruitment processes to exploring alternative AI models and discussing challenges with existing ones, the community is actively engaged in sharing experiences and seeking solutions. Key areas of focus include performance issues, model reviews, efficient prompt engineering, API configuration clarity, failure feedback mechanisms, and exploring new datasets. Additionally, advancements in AI models, training techniques, and community engagement initiatives are driving conversations around AI's evolving landscape and its impacts on various industries.
Unit Testing Importance and RAG Implementation
Unit testing is crucial for mitigating stochasticity in LLM applications, highlighted in a blog post detailing building and testing a RAG app with CircleCI. Proper unit testing is emphasized to prevent unexpected behaviors in AI applications. The discussion underlines a commitment to quality and reliability in AI-driven projects. Vectara-Agentic library simplifies RAG implementation by providing tools to construct agents capable of planning and tool use compatible with various model providers, allowing developers to implement RAG solutions more efficiently. Additionally, running a Local LLM is noted to significantly reduce costs compared to OpenAI services, with total cost of ownership (TCOS) playing a vital role in decision-making. This trend emphasizes the optimization of AI solutions for better cost efficiency.
Challenges Faced in Utilizing Aider
Scripting Aider for Command Execution:
Users can utilize Aider's command line --message argument to automate tasks, sending single instructions directly to the tool.
- For batch processing, simple shell scripts can be employed to apply commands across multiple files.
Using Clipboard to Paste in Aider:
To streamline input, users are encouraged to use the /clipboard command for inserting text from the clipboard into the chat.
- This method allows for maintaining context and minimizing repetitive copy-pasting in terminal workflows.
Configuration Options for Aider:
Aider's configuration can include flags to automatically confirm actions or suppress prompts, potentially enhancing workflow efficiency.
- The
.aider.conf.yamlfile supports options for 'yes to every confirmation' but currently lacks a fine-tuned toggle for specific command types.
Challenges with LLM Model Responses:
Users noted inconsistencies in LLM responses, particularly when using models like Llama3.1 that default to diff instead of whole file edits.
- Manual commands such as
/chat-mode wholehelp alleviate some of these issues by switching the expected response format.
Integrating Temporary Files for Prompts:
For convenience, users can write prompts in a text file and execute them with Aider using the /run command for better clarity.
- This method allows users to maintain context while preventing the need for constant manual input.
Issues and Optimizations in AI Model Training
This section discusses various issues and optimizations encountered during AI model training and development:
-
Scaling Laws and Llora Rank Exploration: Users explore scaling laws to estimate the Llora rank that minimizes test loss, highlighting the impact of high rank on overfitting.
-
Skepticism Toward Direct Preference Optimization: Doubts are raised about Direct Preference Optimization (DPO) with a recommendation to consider KTO as an alternative.
-
Comparison of DPO Loss Types: Members seek experiences with different DPO loss types, indicating the need for insights before testing these methods.
These discussions reflect ongoing efforts to enhance AI model training and performance. Furthermore, the link to the DPO Trainer resource provides additional context and information on the topic.
Challenges in Fine-tuning Models
- Members shared experiences with fine-tuning models like Llama-3.1, noting the difficulty in achieving better performance than the base model.
Model Evaluations and Performance Insights
This section delves into various discussions and findings related to model evaluations and performance insights. It includes suggestions to adjust hyperparameters for optimizing model outcomes, highlighting the QLoRA model outperforming traditional LoRA methods. There are debates on comparative performance metrics between QLoRA, full fine-tuning, and original models, with a focus on percentage differences. Additionally, frustration is voiced regarding incorrect ratings of models like o1-preview by judges, leading to experiments to establish consistent evaluation methods. Concerns are raised about the reasoning boundaries in language models potentially leading to incorrect scoring in evaluations.
Challenges and Solutions in CUDA Development
The discussions in this section cover various challenges encountered in CUDA development and proposed solutions. Topics include the performance degradation of CUDA Graphs, suggestions for profiling CUDA graphs and Triton kernels, utilizing cached kernel calls to reduce overhead, experimenting with multistreaming in Torch, and default NVCC flags affecting Torch extensions. Additionally, advancements in INT8 mixed-precision training, the potential of combining INT8 with other techniques, and the struggle with Triton's overhead are addressed. The section also delves into projects like GameGen-O for open-world video game creation, Larry Ellison's appeal for GPUs, and introducing beginners to custom CUDA kernel training. Progress updates on Llama 3 support, implementation of RMSNorm, and GQA within the CUDA kernel framework showcase ongoing developments in the CUDA community.
LM Studio and Hardware Discussions
This section covers various discussions related to LM Studio and hardware topics. In LM Studio discussions, users troubleshoot GPU acceleration issues and explore model compatibility and performance. They also discuss using LM Studio on Linux, managing long prompts, and sharing resources to enhance LLM usage. On the hardware side, conversations revolve around the potential of different hardware components like the Strix Halo APU for running AI models, the performance of NVIDIA RTX 4090 with LLMs, comparisons of power supply units, RAM requirements for large models, and water cooling solutions for GPUs.
OpenAI and LLM Discussion
The section discusses various topics related to OpenAI, structured outputs, ChatGPT, Voice Mode API, and the O1 Meetup. Insights into the differences between structured outputs and function calling are explored, along with the Voice Mode API's interactive capabilities. Additionally, strategies for scaling ChatGPT, including latency and caching techniques, are highlighted. The community also reflects on the O1 emergency meetup, sharing insights and solutions for developing with OpenAI tools.
Cohere API Discussions
links mentioned: - Minimap.ai: no description found - Cookbooks — Cohere: no description found - Datasets — Cohere,): The document provides an overview of the Dataset API, including file size limits, data retention policies, dataset creation, validation, metadata preservation, using datasets for fine-tuning models, d... - Deployment Options: Our solutions provide industry-leading data privacy and security and are designed to meet the diverse needs of organizations seeking to harness the power of generative AI. Whether you’re a start-up or... - Updates to the Command R Series: The latest versions of the Command R model series offer improvements across coding, math, reasoning, and latency. - CohereForAI/c4ai-command-r-08-2024 · Hugging Face: no description found - CohereForAI/c4ai-command-r-plus-08-2024 · Hugging Face: no description found - Pricing: Access our models directly through our API to create scalable production workloads. - Introducing Safety Modes: Cohere Safety Modes provides enterprise customers with greater control over model guardrails. - Command models get an August refresh — Cohere: no description found
Eleuther Scaling Laws
Looped computation with KV cache
- A member expressed a desire for an architecture capable of looped computation with KV cache, pointing out a current gap in existing capabilities. This highlights ongoing challenges in efficiently handling complex algorithms within machine learning frameworks.
Running Complex Algorithms on Small VMs
- In response to the previous comment, a member mentioned that complex algorithms can still be executed on a small fixed VM effectively, utilizing available resources. This led to a clarification of the term VM, contributing to the technical discussion.
Exploration of Model Sizes for World Models
- One member shared insights about the impractically large model size required (around 8T parameters) for accurate world modeling from diverse sensors. They noted that while current models lack the capacity to infer unintended information, a sufficiently large model could tap into external data sources.
Inquiry for Literature on Scaling Laws
- A member sought recommendations for literature on scaling laws, stating familiarity with training models and interest in sparse autoencoders and mutual information. They already have 'Scaling Laws for Autoregressive Generative Modeling' on their reading list and are eager for additional resources.
Inquiries and Discussions on Various AI Topics
The discussions in this section cover a wide range of topics related to AI and machine learning. Members explored concepts such as agentic thought chains, attention implementation concerns, special tokens for pretraining, and the impact of fused cross entropy. Additionally, inquiries were made about tokenization errors, Phi 3.5 training challenges, and struggles with vLLM and trained adapters. The section also addressed issues with PDF table reading, table data comparisons, and time consumption in data processing. Furthermore, members shared insights on run-time type checking in Tinygrad, test failures on AMD, and discussions around GitHub pull requests. The content spans from exploring illusions in generative AI art to anomaly detection techniques in ML operations.
Issues with Function Calling
This section discusses the limitations caused by an inability to call functions due to bugs, resulting in a score of 0 for other capabilities. It also highlights the critical failure in the model's ability to execute functions effectively, impacting user experience. The discussion on Gorilla LLM (Berkeley Function Calling) addresses errors such as the model producing chat instead of function calls, leading to issues in response processing. Additionally, an 'Invalid syntax' error triggered AST decoder failure, indicating a critical problem in interpreting the model's output.
FAQ
Q: What is the o1 Model?
A: The o1 Model is a model inspired by OpenAI's Llama-3.1 and powered by Groq's hardware, developed by Benjamin Klieger.
Q: What are some advancements in the field of AI models discussed in the essai?
A: Advancements like Llama 3.1 405B running on Apple Silicon hardware, g1 model development, and discussions around potential fine-tuned versions like o1-preview were highlighted.
Q: What are some challenges faced with LLM model responses?
A: Users noted inconsistencies, especially with models defaulting to diff instead of whole file edits, and discussed manual commands like `/chat-mode whole` to address these issues.
Q: How can users streamline input in Aider using the clipboard?
A: Users can use the `/clipboard` command in Aider to insert text from the clipboard into the chat, maintaining context and reducing repetitive copy-pasting in terminal workflows.
Q: What are some discussed topics related to CUDA development and solutions?
A: Discussions included the performance degradation of CUDA Graphs, profiling CUDA graphs and Triton kernels, utilizing cached kernel calls, experimenting with multistreaming in Torch, and addressing default NVCC flags affecting Torch extensions.
Q: What were the findings related to LM Studio and hardware discussions?
A: Users troubleshooted GPU acceleration issues, explored model compatibility and performance in LM Studio, discussed hardware components like the Strix Halo APU, NVIDIA RTX 4090 performance with LLMs, power supply units, RAM requirements, and water cooling solutions for GPUs.
Q: What were some insights shared about open-world video game creation and custom CUDA kernel training?
A: The essai touched on projects like GameGen-O for open-world video game creation, Larry Ellison advocating for GPUs, and introducing beginners to custom CUDA kernel training.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!